
TMDB is a huge database of film and television data that is entirely powered by its users. TMDB is a website that offers a free API gateway (method) for academics who want to get access to movie information.
A database of popular TV series can be found on the website www.themoviedb.org/tv. In this blog, we will use web scraping services to extract TV shows data from the TMDB website. Web Scraping data is the method of collecting information from websites using Python, BeautifulSoup, and Pandas programing language.
To extract TMDB information from the website, you will require Python packages Requests and BeautifulSoup.
Follow the below steps to extract the TMDB data using Python script.
Step 1: Download the webpage using requests.
Step 2: Use BeautifulSoup to read the HTML code.
Step 3: You will check the websites that will include various kinds of information on TV shows. The data will include user scores, will display individual page URLs, and launch dates for every program. You can also scrape latest season episodes, latest season, tagline, cast, and Genre from every show’s page.
Step 4: Create Python groups and dictionaries with the data you have collected.
Step 5: Data from various pages are extracted and combined.
Step 6: Finally, you will need to save the information to a CSV file.
Downloading the Webpage using “requests”
For downloading the webpage, use the requests library. Also, pip will be used to install the library.
!pip install requests --upgrade --quiet
For downloading a webpage, you can choose to employ the get function from requests. Requests.get will replay with a response object that will contain the information from the website and other details.
import requests
# The library is now installed and imported.
# sometimes websites stop you from extracting the data for some reason. It can be due to some authentication errors.
needed_headers = {'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"}
response = requests.get("https://www.themoviedb.org/tv", headers = needed_headers
For a successful response, use the status_code property. The HTTP status code for a successful response will be between 200 and 299.
response.status_code 200 The request was successful. We can get the contents of the page using response.text. dwn_content = response.text len(dwn_content) 223531
Check first 500 characters of the data that you downloaded as above.
dwn_content[:500] '<!DOCTYPE html> \n <html lang="en" class="no-js"> \n <head> \n <title>Popular TV Shows — The Movie Database (TMDB)</title> \n <meta http-equiv="X-UA-Compatible" content="IE=edge" /> \n <meta http-equiv="cleartype" content="on"> \n <meta charset="utf-8"> \n \n <meta name="keywords" content="Movies, TV Shows, Streaming, Reviews, API, Actors, Actresses, Photos, User Ratings, Synopsis, Trailers, Teasers, Credits, Cast"> \n <meta name="mobile-web-app-capable" content="yes"> \n <meta name="'
Here, you will be able to download the page using the request library.
Executing the HTML Source Code Using BeautifulSoup
Use ‘BS4’ for importing the BeautifulSoup library and run the HTML file.
!pip install beautifulsoup4 --upgrade --quiet from bs4 import BeautifulSoup
To execute the HTML source code you will need to use the BeautifulSoup() function which considers two arguments.
Page content and ‘HTM.parser’
test_doc = BeautifulSoup(response.text, 'html.parser') type(test_doc) bs4.BeautifulSoup
The below code will help you extract the title and first image link of the webpage that you will execute into test_doc.
test_doc.find('title')
<title>Popular TV Shows — The Movie Database (TMDB)</title>
test_doc.find('img')
<img alt="The Movie Database (TMDB)" height="20" src="/assets/2/v4/logos/v2/blue_short-8e7b30f73a4020692ccca9c88bafe5dcb6f8a62a4c6bc55cd9ba82bb2cd95f6c.svg" width="154"/>
Using all the data, you will be able to create a function that will help you download webpage data using request and BeautifulSoup. Also, it will return a BeautifulSoup type object for any website link.
def get_page_content(url):
# In this case , we are going to give request.get function headers to avoid the Status code Error 403
get_headers = {'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"}
response_page = requests.get(url, headers = get_headers )
# we are going to raise exception here if status code gives any value other than 200.
if not response_page.ok:
raise Exception ("Failed to request the data. Status Code:- {}".format(response_page.status_code))
else:
page_content = response_page.text
doc_page = BeautifulSoup(page_content, "html.parser")
return doc_page
Executing the function
popular_shows_url = "https://www.themoviedb.org/tv" doc = get_page_content(popular_shows_url)
Here you will retrieve the page’s title once more to ensure that the function was executed successfully.
#let's try to get the title of the page to check if our function works. doc.title.text 'Popular TV Shows — The Movie Database (TMDB)'
You will successfully parse the HTML by employing BeautifulSoup and extracting the TV shows data from the website.
Extracting Every Data from the Webpages
Now we will extract the piece of data such as the program’s title, user score, show’s individual page URL, and other debut dates that can be displayed.
We can find the class required to extract the show's title by studying the web page (by looking at the HTML code), which is card style _1.
We may use the 'h2' and 'p' tags with the class 'card style_1' to acquire show titles and premiere dates, respectively.
Let's make some utility methods to extract data out from page.
We can use the 'h2' and 'p' tags with the class 'card style 1' to acquire show titles and premiere dates...
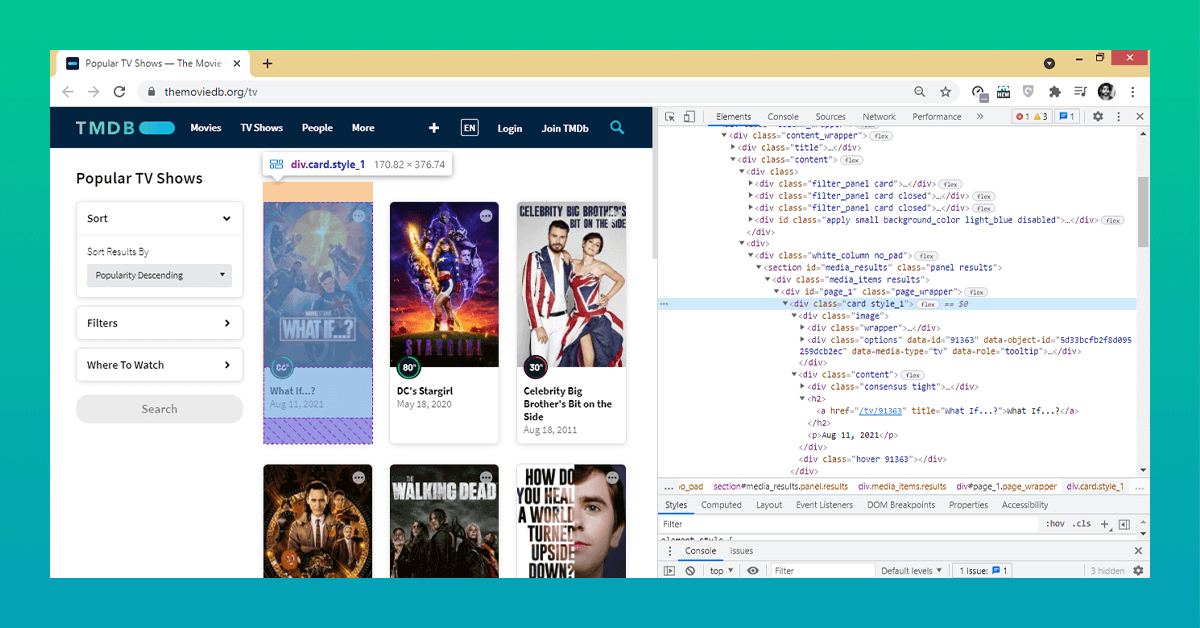
The word 'squid Game' appears in the column beneath our title; the sequence of the shows changes with time, so it may differ in your instance.
# Now that we know the class let's trty to get the title of the first movie.
doc.find_all('div', {'class': 'card style_1'})[0].h2.text
We just need to alter the 'p' tag for the debuted date because it also belongs to the class 'card style_1'.
With the aid of the class User_score_chart, we can retrieve the show's user rating and then the value of the property "data-percent."
doc.find_all('div', {'class': 'user_score_chart'})[0]['data-percent']
'79.0'
All of the data we're retrieving must go somewhere, which is where dictionaries and python lists come into.
Now we'll make a dictionary with the names of the column in our CSV file as keys and the data we'll scrape/extract from the web page as values. It's just a Python 'dict' variable that will contain all of our data, which we'll subsequently employ to construct a DataFrame and CSV.
def empty_dict():
scraped_dict = {
'Title': [],
'User_rating': [],
'Release_date':[],
'Current_season': [],
'Current_season_Episodes': [],
'Tagline': [],
'Genre': [],
'Cast': []
}
return scraped_dict
If you look at the function, then you will see that all of them might not be rated. Here, we will write a function to solve the issue.
If we look at a variety of shows, we'll see that not all of them have been rated yet.
Let's write a function to solve this issue. We can skip a program that hasn't been rated yet or let it display a message if it hasn't been rated yet.
The user's score will be parsed into the dictionary by the function. When we need to develop a final function, the function will come in help.
def user_score_info(tag_user_score, i, scraped_dict):
if tag_user_score[i]['data-percent'] == '0':
scraped_dict['User_rating'].append('Not rated yet')
else:
scraped_dict['User_rating'].append(tag_user_score[i]['data-percent'])
The URL of the particular page of the show, to acquire the rest of the page information, is another piece of the information you will require this page.
This can also be done using the class “card style_1” we will need to acquire the value of the h2 tag’s property “herf.”
doc.find_all('div', {'class': 'card style_1'})[0].h2.a['href']
'/tv/93405'
The output seen above is the last part of the URL of a show. We can construct a helper function to collect these details for each show in a list using the data you have gathered so far.
def get_show_info(doc_page):
base_link_1 = "https://www.themoviedb.org"
tag_title = tag_premired_date = tag_shows_page = doc_page.find_all('div', {'class': 'card style_1'})
tag_user_score = doc_page.find_all('div', {"user_score_chart"})
doc_2_list = []
for link in tag_shows_page:
# here we are creating the list of all the individual pages of the shows which will come handy in other functions.
doc_2_list.append(get_page_content("https://www.themoviedb.org" + link.h2.a['href']))
# we are going to have the function to return the list of all the information as elements.
return tag_title, tag_user_score, doc_2_list
# lets see if the function returns the list of the information we tried to get earlier.
len(get_show_info(doc))
Extracting the Current_season, Current_season_Episodes, Tagline, Genre, Cast.
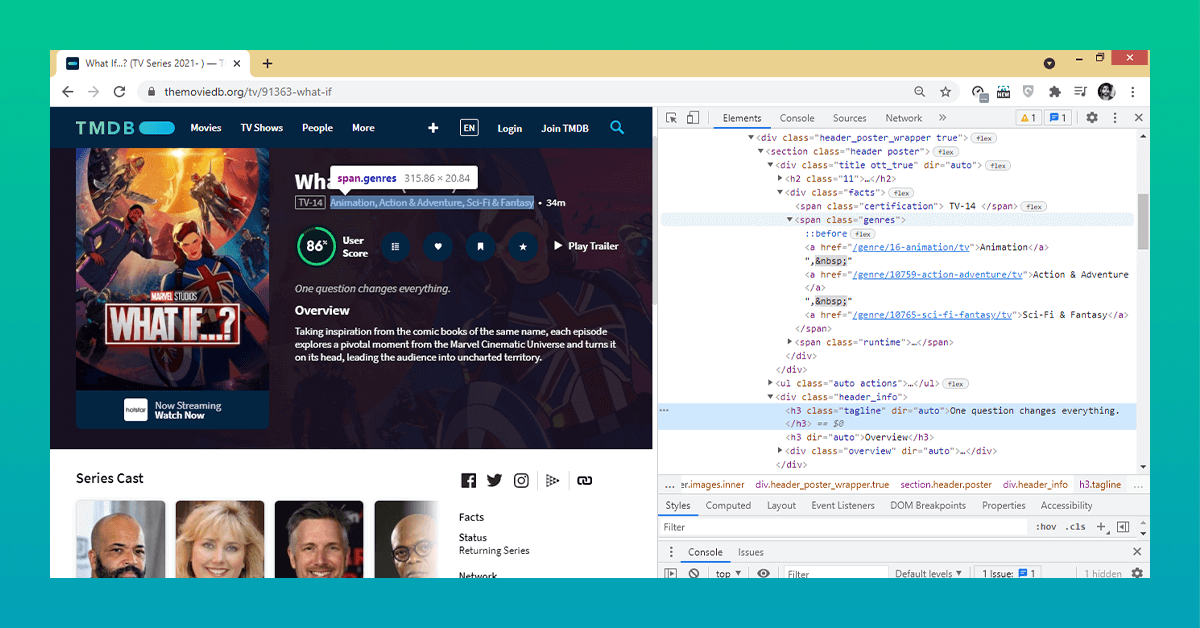
Here, we will scrape Current_season, Current_season_Episodes, Tagline, Genre, Cast from the list of individual program URLs.
Let's start with the show's genre and slogan. "Genres" and "tagline" are the classes we'll use for this. For a better understanding, look at the graphic below.
doc 2 = get page content("https://www.themoviedb.org/tv/91363")
As we can see, the 'a' tag under the class 'genres' has several values for the show's genre. Let's make a genre list.
tag_genre = doc_2.find('span', {"class": "genres"})
tag_genre_list = tag_genre.find_all('a')
check_genre =[]
for tag in tag_genre_list:
check_genre.append(tag.text)
check_genre
['Animation', 'Action & Adventure', 'Sci-Fi & Fantasy']
A collection type variable in the code cell below doc2 page includes a list of individual web pages for each show.
# lets create a function to get the genres for the show.
# i here denotes the element of the list vairable ``doc2_page`` that contains different doc pages. Will come handy later on.
def get_genres(doc2_page, i):
genres_tags = doc2_page[i].find('span', {"class": "genres"}).find_all('a')
check_genre =[]
for tag in genres_tags:
check_genre.append(tag.text)
return check_genre
We'll need the show's tagline for the following piece of information, but some movies don't have it yet. Let's make a function for this and use if else statements to solve the problem. The method will parse the value and save it in the dictionary we made before.
tag_tagline = doc_2.find('h3',{"class": 'tagline'})
def tagline_info(doc_2_list, i, scraped_dict):
if doc_2_list[i].find('h3',{"class": 'tagline'}):
scraped_dict['Tagline'].append(doc_2_list[i].find('h3',{"class": 'tagline'}).text)
else:
scraped_dict['Tagline'].append("No Tagline")
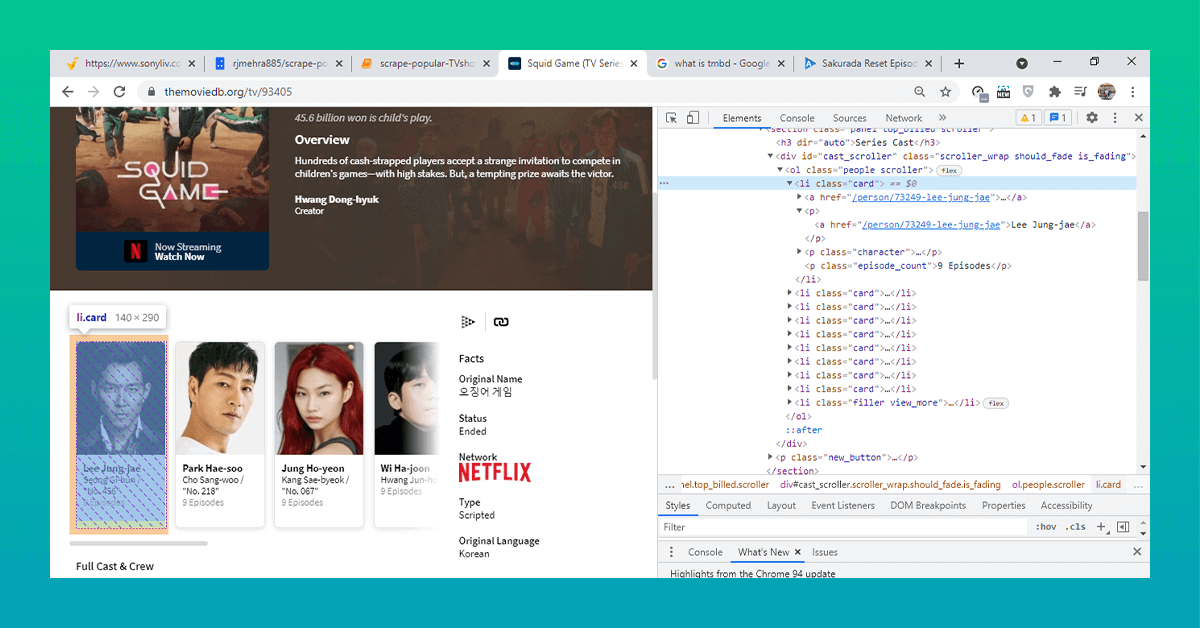
If we investigate the HTML of a TV show's web page, we can extract the list of cast using the class 'card' and tag 'li', much way we got the list of genres and then a function for it.
Let's make a function to fetch the show's cast.
# i here denotes the the element of the list type variable``doc2_page`` that contains different doc pages.
def get_show_cast(doc2_page, i):
cast_tags = doc2_page[i].find_all('li', {'class': 'card'})
cast_lis = []
for t in cast_tags:
cast_lis.append(t.p.text)
return cast_lis
We'll scan 'current season' and its episodes for a few last bits of information. We may find it in the "flex" class. For a better understanding, look at the graphic below.
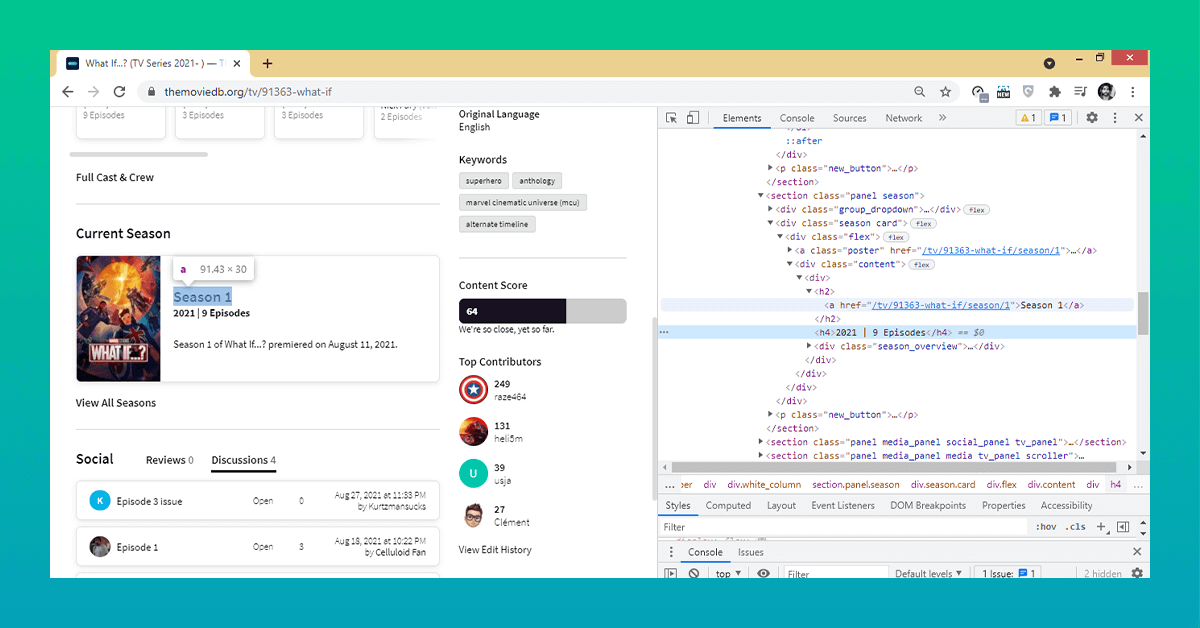
It's quite easy and simple to retrieve the text section of the "h2" tag for "current season."
However, when we look carefully at the image above, you can have something for the current season's episodes, things get a bit more complicated since the year is included in front of the episode number.
We're going to remove that section so we're only left with the number of episodes. For a better understanding, look at the cells below.
tag_episodes = doc_2.find_all('div' , {'class': 'flex'})
# extracing current season from h2 tag under class flex.
tag_episodes[1].h2.text
'Season 1'
As can be seen in the code cell below, it not only gives the number of programs but also the year they were produced. This is the same format for all of the shows on the website. You will just be interested in the quantity of episodes, not the year. Let's leave out the year.
print('2021 | 9 Episodes'[7:])
tag_episodes[1].h4.text[7:]
9 Episodes
'9 Episodes'
We can now extract all data you require from each show using this method. All we need to do now is figure out how to acquire everything at once for each show.
Merge Extracted Data into Python Lists and Dictionaries
We have retrieved show information from many web pages. The next step is to collect all or most of the show's data and save it in a dictionary so which we can use it to produce a CSV file later. We'll put everything together in a function.
The function returns a DataFrame that has been built with the help of a dictionary. CSV files may also be created with DataFrame. For additional information about DataFrames, see the link below.
Now you have to collect all the data you need from a television program. Create a function that will extract all the data and deliver a DataFrame.
import pandas as pd
def get_show_details(t_title, t_user_score, docs_2_list):
# excuting a function here that empties the dictionary every time the function is called.
scraped_dict = empty_dict()
for i in range (0, len(t_title)):
scraped_dict['Title'].append(t_title[i].h2.text)
user_score_info(t_user_score, i, scraped_dict)
scraped_dict['Release_date'].append(t_title[i].p.text)
scraped_dict['Current_season'].append(docs_2_list[i].find_all('div' , {'class': 'flex'})[1].h2.text)
scraped_dict['Current_season_Episodes'].append(docs_2_list[i].find_all('div' , {'class': 'flex'})[1].h4.text[7:])
tagline_info(docs_2_list, i, scraped_dict)
scraped_dict['Genre'].append(get_genres(docs_2_list, i))
scraped_dict['Cast'].append(get_show_cast(docs_2_list, i))
return pd.DataFrame(scraped_dict)
We must first learn how to construct a CSV file before we can use our method get show details(). Fortunately, with Python, it's as simple as using the function.to csv('path/csv file name') on a dataFrame.
Every file must be saved in a directory with a path, and even if the path is not provided to the.to csv() function, it will use the system's default path. With the aid of read csv('file path'), you can may a CSV file which has been generated.
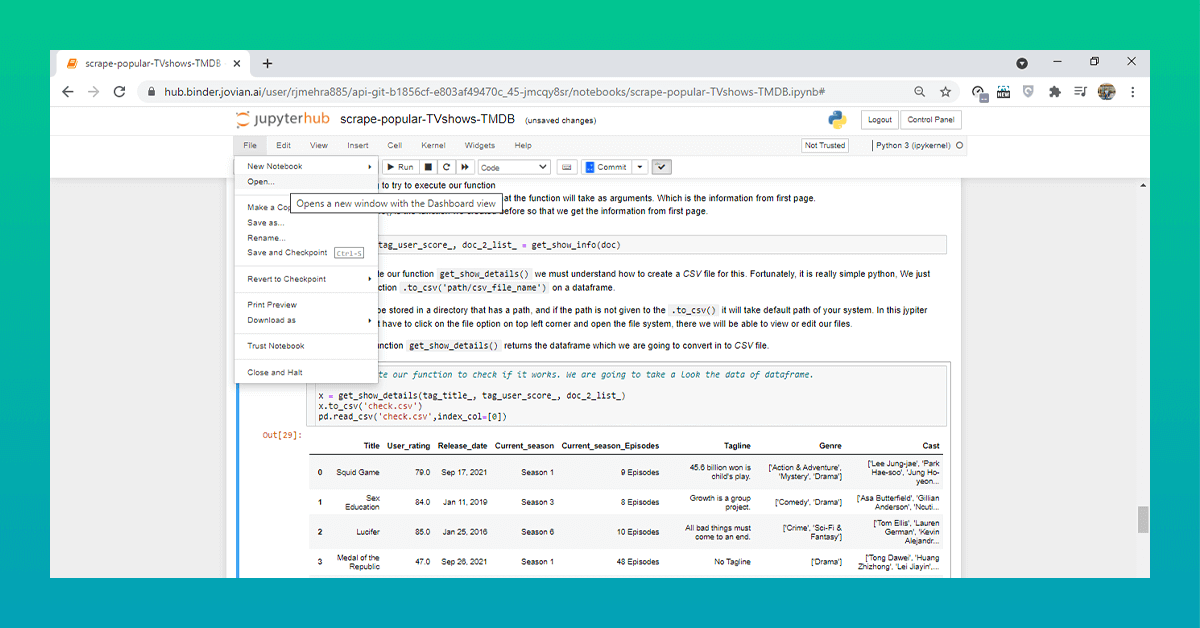
# Let's excute our function to check if it works. We are going to take a look the data of dataframe.
x = get_show_details(tag_title_, tag_user_score_, doc_2_list_)
x.to_csv('check.csv')
pd.read_csv('check.csv',index_col=[0])
You will need to use OS to interact with directories and files, allowing us to create and delete certain folders on our system. .makedirs('directory name', exist ok = True) may be used to build a directory for our CSV files.
You will write a function that takes an empty list, generates a DataFrame, and transforms it to a CSV file that we can put in a folder.
The DataFrame will be appended to the list by the function.
Now, this method will scrape the programs from the website that is typically not displayed on the site unless we click on a button that is designed to display the list of shows on the following page using the various methods we developed.
For doing so, append “?page=page number? To the end of the URL.
Download the Data to a CSV File
This is the last section of our web scraping article. We'll write a function that extracts a whole website, including every show's particular web page, and saves it as a CSV file. Before we start writing a function, there are a few things we need to know:
- To interact with directory services, we'll import the OS module, which will make it possible to create and remove certain folders from our system. .makedirs('directory name', exist ok = True) may be used to build a directory for our CSV files. To learn more about the OS module, click on the following link.
- Now we'll write a function that takes an empty list, creates a Dataframe, and converts it to a CSV file that we can put in a folder.
- The dataframe will be appended to the list by the function.
- Now, this function will leverage all of the previous methods we established to scrape the shows from a page that is typically hidden on the site until we click a button that should load a new list of programs on the following page.
- For doing so, append "?page = page number" to the end of the URL.
import os
base_link = "https://www.themoviedb.org/tv"
# 'i' here means the number of page we want to extract
def create_page_df( i, dataframe_list):
os.makedirs('shows-data', exist_ok = True)
next_url = base_link + '?page={}'.format(i)
doc_top = get_page_content(next_url)
name_tag, viewer_score_tag, doc_2_lis = get_show_info(doc_top)
print('scraping page {} :- {}'.format(i, next_url))
dataframe_data = get_show_details(name_tag, viewer_score_tag, doc_2_lis)
dataframe_data.to_csv("shows-data/shows-page-{}.csv".format(i) , index = None)
print(" ---> a CSV file with name shows-page-{}.csv has been created".format(i))
dataframe_list.append(dataframe_data)
test_list = []
create_page_df(9 , test_list)
scraping page 9 :- https://www.themoviedb.org/tv?page=9 ---> a CSV file with name shows-page-9.csv has been created
You will be able to extract all of the data from a website and save it to CSV file. In other words, we can do this and extract 20 shows that are visible on the website page, but for the remaining of the websites you will need to click “load more”. We'll finish off by writing a function that scrapes the desired number of pages. Let's have a look at the remaining few stages. The final step in finishing our function is to generate a final CSV file that contains all 200 rows.
In the final function, you will consider a list of Dataframes and convert it to CSV using concat() function.
Want to extract TV shows data?
Get a Quote!The concat() method combines a list of Dataframes into a single large dataframe that may then be translated to a CSV file.
import pandas as pd
base_link = "https://www.themoviedb.org/tv"
def scrape_top_200_shows(base_link):
dataframe_list = []
# we are going to keep range up to 11 because we just need up to 200 TV shows for now.
for i in range(1,11):
create_page_df(i, dataframe_list)
# here we are using concat function so that we can merge the each dataframe that we got from the each page.
total_dataframe = pd.concat(dataframe_list, ignore_index = True)
# with the simple command of to_csv() we can create a csv file of all the pages we extracted.
csv_complete = total_dataframe.to_csv('shows-data/Total-dataframe.csv', index= None)
print(" \n a CSV file named Total-dataframe.csv with all the scraped shows has been created")
Let's place the last function to the test now that we've completed all of the functions.
scrape_top_200_shows(base_link) scraping page 1 :- https://www.themoviedb.org/tv?page=1 ---> a CSV file with name shows-page-1.csv has been created scraping page 2 :- https://www.themoviedb.org/tv?page=2 ---> a CSV file with name shows-page-2.csv has been created scraping page 3 :- https://www.themoviedb.org/tv?page=3 ---> a CSV file with name shows-page-3.csv has been created scraping page 4 :- https://www.themoviedb.org/tv?page=4 ---> a CSV file with name shows-page-4.csv has been created scraping page 5 :- https://www.themoviedb.org/tv?page=5 ---> a CSV file with name shows-page-5.csv has been created scraping page 6 :- https://www.themoviedb.org/tv?page=6 ---> a CSV file with name shows-page-6.csv has been created scraping page 7 :- https://www.themoviedb.org/tv?page=7 ---> a CSV file with name shows-page-7.csv has been created scraping page 8 :- https://www.themoviedb.org/tv?page=8 ---> a CSV file with name shows-page-8.csv has been created scraping page 9 :- https://www.themoviedb.org/tv?page=9 ---> a CSV file with name shows-page-9.csv has been created scraping page 10 :- https://www.themoviedb.org/tv?page=10 ---> a CSV file with name shows-page-10.csv has been created a CSV file named Total-dataframe.csv with all the scraped shows has been created
We were able to effectively develop a function as well as all of the necessary csv files. Let's take one more glance at how our entire CSV file looks with the aid of pandas. read csv()
pd.read_csv('shows-data/Total-dataframe.csv')[0:50]
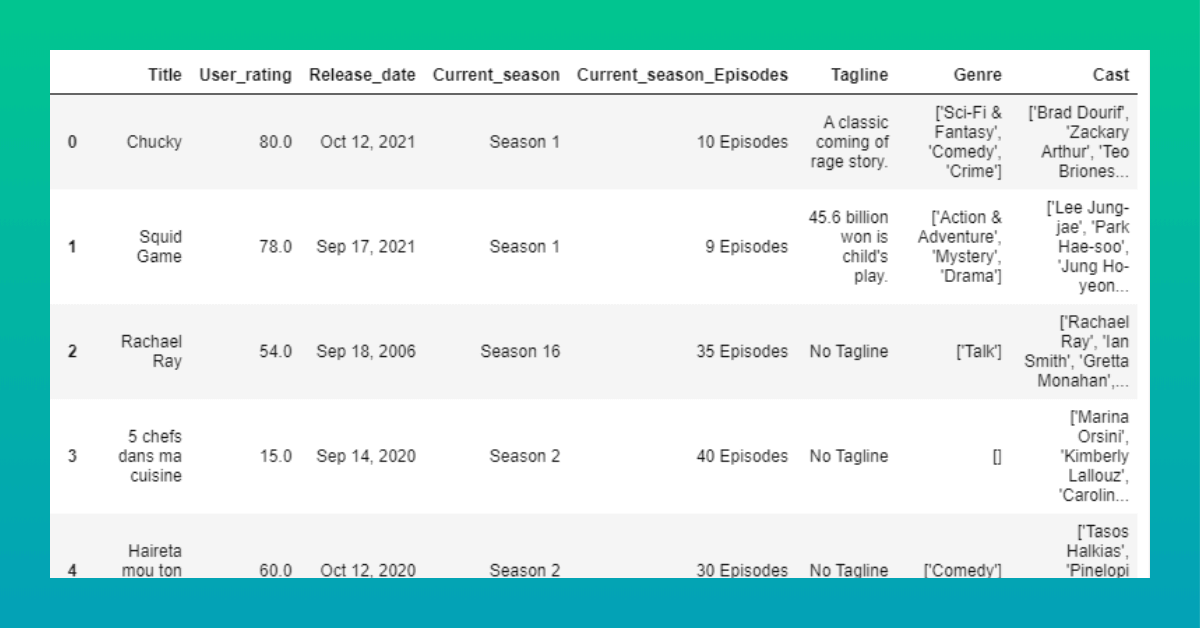
That is all there is to it. Now, all we need is a single function that we developed at the very end. We were able to scrape 10 pages/200 shows successfully. We could have scraped a lot more pages, but we kept it at a modest level to keep it legible.
Requests were used to download the webpage.
Beautifulsoup was used to parse the HTML source code.
Summary
We looked at the website with the TV show schedule. We extracted the title, User Score, show's individual page URL, and launch date for each program.
We gathered information on the program from each unique page URL. Current season, Current season Episodes, Tagline, Genre, and Cast are just a few examples.
Into python lists and dictionaries, I compiled the retrieved data.
Data from different pages was extracted and blended.
The extracted data was saved to a CSV file called Total-dataframe.csv.
If you are looking to extract TV Shows data on TMDB using Python then contact Scraping Intelligence or request for a quote!!!




