
TikTok is among the most prominent social media sites, with huge visits per user and popularity. Thus, it is helpful for businesses and researchers to obtain data from TikTok and similar social media platforms. Web scraping is the collection of information from websites. As a social media platform that has surged rapidly in recent years and has hundreds of millions of users, TikTok is a gold mine of data.
This blog will explain how to scrape TikTok content with Python Playwright, a progressive browser automation library.
What is TikTok Data Scraping?
TikTok scraping is a process of gathering information from the TikTok database using automated tools or scripts. This data can contain the users’ profile information, videos, comments, hashtags, and engagement statistics, such as likes, shares, and views. With extensive data, businesses and researchers can observe trends, use behaviors, and the popularity of specific content in the application.
TikTok scraping is the process of gathering different sorts of data from the platform, such as users’ profiles, video information, comments, likes, and search tags. Such information can be the name and text of the profile, the number of subscribers, and demographic data, including age, gender, place of living, and interests of TikTok users. Moreover, it includes short-form videos with captions, likes, comments, shares, views, and hashtags related to the classification of contents and text response to videos.
How Tiktok Data Scraping Helps Businesses?
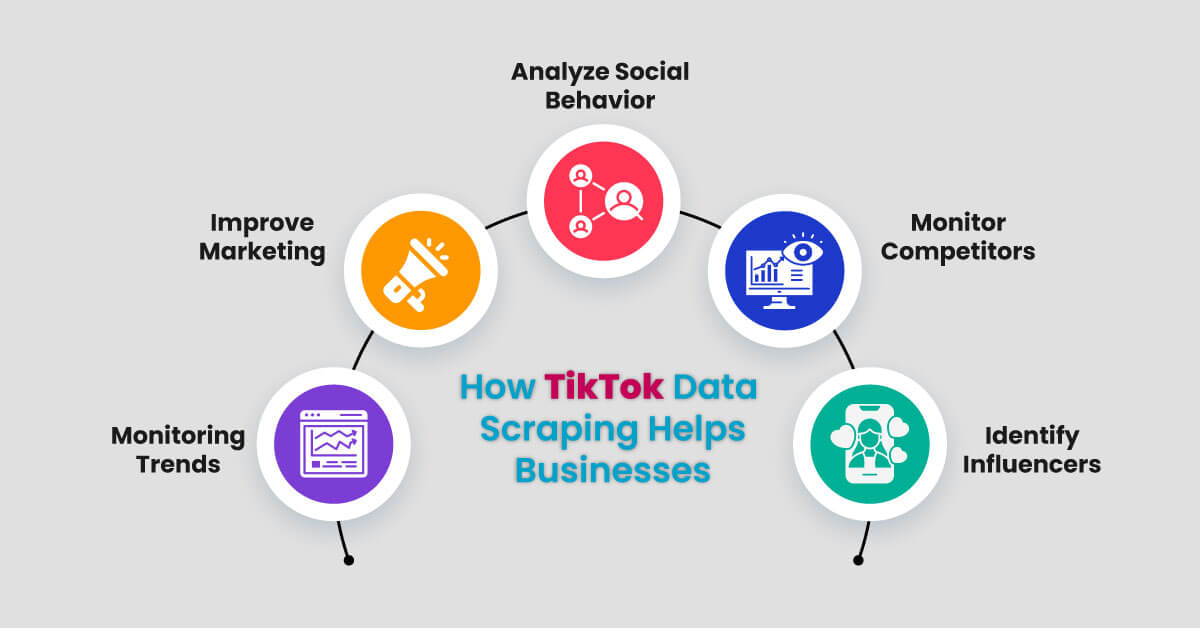
TikTok has a vast amount of data that can be scraped by utilizing advanced web scraping practices. Businesses can use TikTok data scraping services to stay ahead of the competition and ensure informed decision-making processes.
Monitoring Trends
Scraping TikTok data enables the company to know what’s popular, including trending videos and hashtags. In this way, they can generate more content that will go viral and, therefore, be liked and shared.
Improve Marketing
Analyzing the trends popular on TikTok will help companies better understand how to adjust advertising campaign plans to appeal to the audience, gain more followers, and attract more customers.
Analyze Social Behavior
This method allows academicians to gain insight into how people engage, what is important to them, and how things go viral on the TikTok platform. This assists them in understanding specific engagements of social/cultural respect.
Monitor Competitors
That is helpful for businesses as they can monitor what their competitors are up to on TikTok. It can view what strategies the competitors use are effective and adapt its strategy correspondingly.
Identify Influencers
Collecting data from TikTok allows for the definition of the most popular profiles that can become managers and promote goods and services. Organizations can partner with these influencers to promote their brand further and reach a larger audience.
How Do You Scrape TikTok Data by Leveraging Python?
To scrape TikTok data, we will use a few Python libraries and setup them for a smooth Tiktok data scraping process:
- httpx: This is for making HTTP calls to TikTok and receiving either HTML or JSON data.
- parsel: When getting elements and understanding HTML’s layout using selectors like XPath or CSS.
- JMESPath: Regarding manipulating the obtained source JSON data to remove unneeded information.
- loguru: This is for supervising and keeping a record of our TikTok scraper in pretty terminal visualizations.
- asyncio: It is used to increase our web scraping process by running our code in parallel, i.e., asynchronously.
Here, you also need to recall that asyncio is a built-in Python library, so it is unnecessary to install it separately. Use the following command to install the other packages:
pip install httpx parsel jmespath loguru
How to Scrape TikTok Profile Data?
It is time to begin constructing the initial segments of the TikTok scraper; this will involve scraping profile pages. Profile pages can include two types of data:
Any profile's primary data should include the name, ID, and number of followers and likes. Channel data if the profile in discussion has made any posts. It contains information on each video, including its name, description, and view statistics.
We should start with the profile data scraping, and the data can be located in JavaScript script tags. To view this tag, follow the below steps:
- For this task, you need to choose any profile on the TikTok application and open it.
- Right-click on the web page you are about to analyze and select ‘inspect’ or press the F12 key.
- Search for the script tag with the keyword that contains the __UNIVERSAL_DATA ID at the beginning.
- Such a format includes all the general info concerning the web app, a browser, and localization. However, the profile data can be retrieved under the web app. User-detail key:
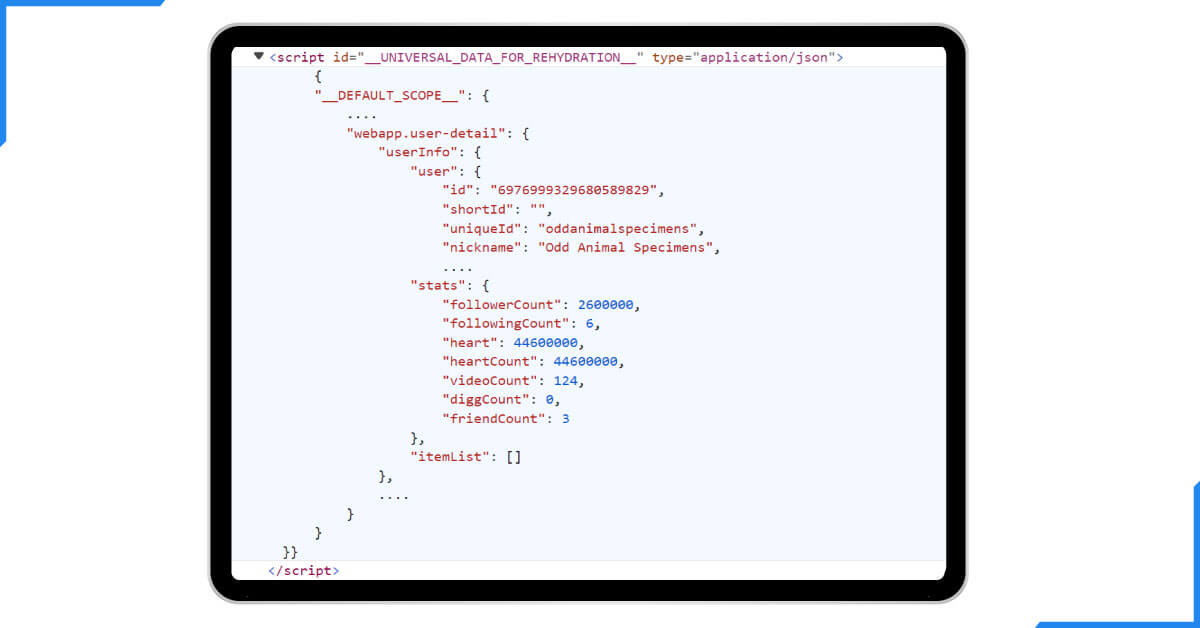
The information above is frequently referred to as "hidden web data." The same data is displayed on the website but not rendered as HTML.
Therefore, we will access the TikTok profile page, choose the script tag containing the data, and parse it to scrape the profile data:
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def parse_profile(response: Response):
"""parse profile data from hidden scripts on the HTML"""
assert response.status_code == 200, "request is blocked, use the ScrapFly codetabs"
selector = Selector(response.text)
data = selector.xpath("//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()").get()
profile_data = json.loads(data)["__DEFAULT_SCOPE__"]["webapp.user-detail"]["userInfo"]
return profile_data
async def scrape_profiles(urls: List[str]) -> List[Dict]:
"""scrape tiktok profiles data from their URLs"""
to_scrape = [client.get(url) for url in urls]
data = []
# scrape the URLs concurrently
for response in asyncio.as_completed(to_scrape):
response = await response
profile_data = parse_profile(response)
data.append(profile_data)
log.success(f"scraped {len(data)} profiles from profile pages")
return data
Let's go through the above code:
- Make an httpx request, async to avoid freezing the browser, and add simple browser headers.
- So, define the parse_profiles function to select the script tag and parse the profile information data.
- This function should be called scrape_profiles. Its main task is to request concurrently the profile URLs and the data on each page.
- Running the above TikTok scraper will generate a JSON file known as profile_data.
Here is what it looks like:
[
{
"user": {
"id": "6976999329680589829",
"shortId": "",
"uniqueId": "oddanimalspecimens",
"nickname": "Odd Animal Specimens",
"avatarLarger": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_1080x1080.jpeg?lk3s=a5d48078&x-expires=1709280000&x-signature=1rRtT4jX0Tk5hK6cpSsDcqeU7cM%3D",
"avatarMedium": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_720x720.jpeg?lk3s=a5d48078&x-expires=1709280000&x-signature=WXYAMT%2BIs9YV52R6jrg%2F1ccwdcE%3D",
"avatarThumb": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_100x100.jpeg?lk3s=a5d48078&x-expires=1709280000&x-signature=rURTqWGfKNEiwl42nGtc8ufRIOw%3D",
"signature": "YOUTUBE: Odd Animal Specimens\nCONTACT: OddAnimalSpecimens@whalartalent.com",
"createTime": 0,
"verified": false,
"secUid": "MS4wLjABAAAAmiTQjtyN2Q_JQji6RgtgX2fKqOA-gcAAUU4SF9c7ktL3uPoWu0nLpBfqixgacB8u",
"ftc": false,
"relation": 0,
"openFavorite": false,
"bioLink": {
"link": "linktr.ee/oddanimalspecimens",
"risk": 0
},
"commentSetting": 0,
"commerceUserInfo": {
"commerceUser": false
},
"duetSetting": 0,
"stitchSetting": 0,
"privateAccount": false,
"secret": false,
"isADVirtual": false,
"roomId": "",
"uniqueIdModifyTime": 0,
"ttSeller": false,
"region": "US",
"profileTab": {
"showMusicTab": false,
"showQuestionTab": true,
"showPlayListTab": true
},
"followingVisibility": 1,
"recommendReason": "",
"nowInvitationCardUrl": "",
"nickNameModifyTime": 0,
"isEmbedBanned": false,
"canExpPlaylist": true,
"profileEmbedPermission": 1,
"language": "en",
"eventList": [],
"suggestAccountBind": false
},
"stats": {
"followerCount": 2600000,
"followingCount": 6,
"heart": 44600000,
"heartCount": 44600000,
"videoCount": 124,
"diggCount": 0,
"friendCount": 3
},
"itemList": []
}
]
TikTok may be effectively scraped for profile information. However, the video data for the profile is missing. Let's take it out!
How to Scrape TikTok Channel Data?
This section will involve scraping the TikTok channel posts. The data we will be scraping will be video data, which are only available in the profile that has a post. Thus, this profile type is called a channel.
The actual data of the channel videos displayed in the channel video list are populated through JavaScript, where scrolling populates more data.
Thus, to gather channel data, the URL of the /post/item_list/ API endpoint should be accessed directly. However, this endpoint needs many parameters, and it is not easy to maintain all of them. Thus, we will have to scrape the data from the XHR calls.
It can be noted that in TikTok, profile pages can be viewed without the user logging into his/her account. However, it only allows actions involving the arrow key when not logged in. The mouse actions are disabled; we can’t scroll down with the keyboard keys. Therefore, we'll scroll down using JavaScript code that gets executed upon sending a request:
function scrollToEnd(i) {
// check if already at the bottom and stop if there aren't more scrolls
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
console.log("Reached the bottom.");
return;
}
// scroll down
window.scrollTo(0, document.body.scrollHeight);
// set a maximum of 15 iterations
if (i < 15) {
setTimeout(() => scrollToEnd(i + 1), 3000);
} else {
console.log("Reached the end of iterations.");
}
}
scrollToEnd(0);
Here, we define a JavaScript function for scrolling. For each scroll iteration, wait for the XHR requests to finish loading. The scroll bar can be up to 15, which is enough for the average profile.
Let's use the above JavaScript code to scrape TikTok channel data from XHR calls:
import jmespath
import asyncio
import json
from typing import Dict, List
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your ScrapFly APi key")
js_scroll_function = """
function scrollToEnd(i) {
// check if already at the bottom and stop if there aren't more scrolls
if (window.innerHeight + window.scrollY >= document.body.scrollHeight) {
console.log("Reached the bottom.");
return;
}
// scroll down
window.scrollTo(0, document.body.scrollHeight);
// set a maximum of 15 iterations
if (i < 15) {
setTimeout(() => scrollToEnd(i + 1), 3000);
} else {
console.log("Reached the end of iterations.");
}
}
scrollToEnd(0);
"""
def parse_channel(response: ScrapeApiResponse):
"""parse channel video data from XHR calls"""
# extract the xhr calls and extract the ones for videos
_xhr_calls = response.scrape_result["browser_data"]["xhr_call"]
post_calls = [c for c in _xhr_calls if "/api/post/item_list/" in c["url"]]
post_data = []
for post_call in post_calls:
try:
data = json.loads(post_call["response"]["body"])["itemList"]
except Exception:
raise Exception("Post data couldn't load")
post_data.extend(data)
# parse all the data using jmespath
parsed_data = []
for post in post_data:
result = jmespath.search(
"""{
createTime: createTime,
desc: desc,
id: id,
stats: stats,
contents: contents[].{desc: desc, textExtra: textExtra[].{hashtagName: hashtagName}},
video: video
}""",
post
)
parsed_data.append(result)
return parsed_data
async def scrape_channel(url: str) -> List[Dict]:
"""scrape video data from a channel (profile with videos)"""
log.info(f"scraping channel page with the URL {url} for post data")
response = await SCRAPFLY.async_scrape(ScrapeConfig(
url, asp=True, country="GB", render_js=True, rendering_wait=2000, js=js_scroll_function
))
data = parse_channel(response)
log.success(f"scraped {len(data)} posts data")
return data
Let's break down the execution flow of the above TikTok web scraping code:
- A request with the headless browser is made to the profile page.
- The JavaScript scroll function pops up.
- Background XHR calls fetch additional channel video data.
- The parse_channel function traverses through all the XHR calls' responses to store the video-related information in the post_data array.
- The ‘‘channel’’ data are further cleaned with JMESPath to exclude incidental information that is not interesting.
- We took a small segment for each video data we obtained from the responses. However, additional fields that include the required details can remain in the complete response.
Here is a sample output for the results we got:
[
{
"createTime": 1675963028,
"desc": "Mouse to Whale Vertebrae - What bone should I do next? How big is a mouse vertebra? How big is a whale vertebrae? A lot bigger, but all vertebrae share the same shape. Specimen use made possible by the University of Michigan Museum of Zoology. #animals #science #learnontiktok ",
"id": "7198206283571285294",
"stats": {
"collectCount": 92400,
"commentCount": 5464,
"diggCount": 1500000,
"playCount": 14000000,
"shareCount": 11800
},
"contents": [
{
"desc": "Mouse to Whale Vertebrae - What bone should I do next? How big is a mouse vertebra? How big is a whale vertebrae? A lot bigger, but all vertebrae share the same shape. Specimen use made possible by the University of Michigan Museum of Zoology. #animals #science #learnontiktok ",
"textExtra": [
{
"hashtagName": "animals"
},
{
"hashtagName": "science"
},
{
"hashtagName": "learnontiktok"
}
]
}
],
"video": {
"bitrate": 441356,
"bitrateInfo": [
....
],
"codecType": "h264",
"cover": "https://p16-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028?x-expires=1709287200&x-signature=Iv3PLyTi3PIWT4QUewp6MPnRU9c%3D",
"definition": "540p",
"downloadAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/ed00b2ad6b9b4248ab0a4dd8494b9cfc/?a=1988&ch=0&cr=3&dr=0&lr=tiktok_m&cd=0%7C0%7C1%7C&cv=1&br=932&bt=466&bti=ODszNWYuMDE6&cs=0&ds=3&ft=4fUEKMvt8Zmo0K4Mi94jVhstrpWrKsd.&mime_type=video_mp4&qs=0&rc=ZTs1ZTw8aTZmZzU8ZGdpNkBpanFrZWk6ZmlsaTMzZzczNEBgLmJgYTQ0NjQxYDQuXi81YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709138858&l=20240228104720CEC3E63CBB78C407D3AE&ply_type=2&policy=2&signature=b86d518a02194c8bd389986d95b546a8&tk=tt_chain_token",
"duration": 16,
"dynamicCover": "https://p19-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/348b414f005f4e49877e6c5ebe620832_1675963029?x-expires=1709287200&x-signature=xJyE12Y5TPj2IYQJF6zJ6%2FALwVw%3D",
"encodeUserTag": "",
"encodedType": "normal",
"format": "mp4",
"height": 1024,
"id": "7198206283571285294",
"originCover": "https://p16-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/3f677464b38a4457959a7b329002defe_1675963028?x-expires=1709287200&x-signature=KX5gLesyY80rGeHg6ywZnKVOUnY%3D",
"playAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/e9748ee135d04a7da145838ad43daa8e/?a=1988&ch=0&cr=3&dr=0&lr=unwatermarked&cd=0%7C0%7C0%7C&cv=1&br=862&bt=431&bti=ODszNWYuMDE6&cs=0&ds=6&ft=4fUEKMvt8Zmo0K4Mi94jVhstrpWrKsd.&mime_type=video_mp4&qs=0&rc=OzRlNzNnPDtlOTxpZjMzNkBpanFrZWk6ZmlsaTMzZzczNEAzYzI0MC1gNl8xMzUxXmE2YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709138858&l=20240228104720CEC3E63CBB78C407D3AE&ply_type=2&policy=2&signature=21ea870dc90edb60928080a6bdbfd23a&tk=tt_chain_token",
"ratio": "540p",
"subtitleInfos": [
....
],
"videoQuality": "normal",
"volumeInfo": {
"Loudness": -15.3,
"Peak": 0.79433
},
"width": 576,
"zoomCover": {
"240": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:240:240.avif?x-expires=1709287200&x-signature=UV1mNc2EHUy6rf9eRQvkS%2FX%2BuL8%3D",
"480": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:480:480.avif?x-expires=1709287200&x-signature=PT%2BCf4%2F4MC70e2VWHJC40TNv%2Fbc%3D",
"720": "https://p19-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:720:720.avif?x-expires=1709287200&x-signature=3t7Dxca4pBoNYtzoYzui8ZWdALM%3D",
"960": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028~tplv-photomode-zoomcover:960:960.avif?x-expires=1709287200&x-signature=aKcJ0jxPTQx3YMV5lPLRlLMrkso%3D"
}
}
},
....
]
The above code extracted over a hundred video data with just a few lines of code in less than a minute. That's powerful!
How To Scrape TikTok Posts?
It's time to move on with our TikTok scraping project. In this section of the web scraping operation, we will scrape video data, which is the posts or content produced by TikTok users. As in the case of profile pages, post data can be revealed as hidden data placed under script tags.
Go to any video on TikTok, inspect the page, and search for the following selector, which we have used earlier:
//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()
This is how the post data appears in the script tag above:
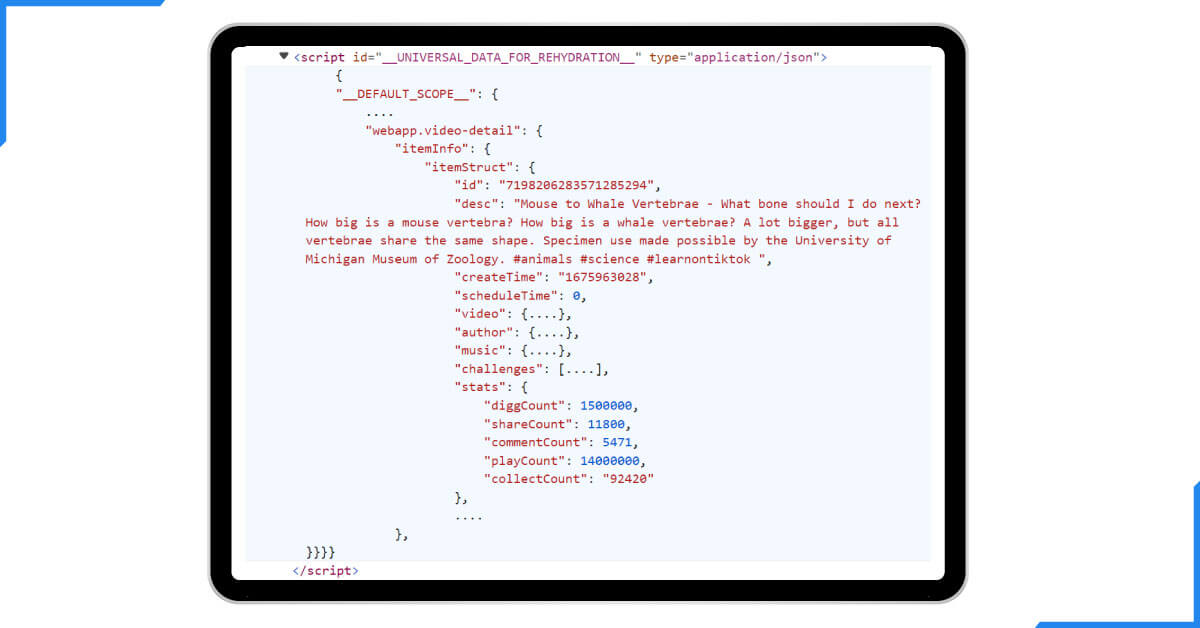
Let's extract and parse the information mentioned above to start scraping TikTok posts:
In the above code, two functions are defined. In the above code, IsNumber is used to check if the character entered is any numeric number. Similarly, IsAlpha is used to check if the character entered has any Alpha letters. Whichever condition is met, it returns True; otherwise, it will return False. Let's break them down:
import jmespath
import asyncio
import json
from typing import List, Dict
from httpx import AsyncClient, Response
from parsel import Selector
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
},
)
def parse_post(response: Response) -> Dict:
"""parse hidden post data from HTML"""
assert response.status_code == 200, "request is blocked, use the ScrapFly codetabs"
selector = Selector(response.text)
data = selector.xpath("//script[@id='__UNIVERSAL_DATA_FOR_REHYDRATION__']/text()").get()
post_data = json.loads(data)["__DEFAULT_SCOPE__"]["webapp.video-detail"]["itemInfo"]["itemStruct"]
parsed_post_data = jmespath.search(
"""{
id: id,
desc: desc,
createTime: createTime,
video: video.{duration: duration, ratio: ratio, cover: cover, playAddr: playAddr, downloadAddr: downloadAddr, bitrate: bitrate},
author: author.{id: id, uniqueId: uniqueId, nickname: nickname, avatarLarger: avatarLarger, signature: signature, verified: verified},
stats: stats,
locationCreated: locationCreated,
diversificationLabels: diversificationLabels,
suggestedWords: suggestedWords,
contents: contents[].{textExtra: textExtra[].{hashtagName: hashtagName}}
}""",
post_data
)
return parsed_post_data
async def scrape_posts(urls: List[str]) -> List[Dict]:
"""scrape tiktok posts data from their URLs"""
to_scrape = [client.get(url) for url in urls]
data = []
for response in asyncio.as_completed(to_scrape):
response = await response
post_data = parse_post(response)
data.append(post_data)
log.success(f"scraped {len(data)} posts from post pages")
return data
- parse_post: This function extracts post data from the script tag and pre-processes it with JMESPath to get only the relevant data.
- scrape_posts: To scrape multiple post pages by putting the URLs into a scraping list and then calling them at once.
Here is what the created post_data file should look like
[
{
"id": "7198206283571285294",
"desc": "Mouse to Whale Vertebrae - What bone should I do next? How big is a mouse vertebra? How big is a whale vertebrae? A lot bigger, but all vertebrae share the same shape. Specimen use made possible by the University of Michigan Museum of Zoology. #animals #science #learnontiktok ",
"createTime": "1675963028",
"video": {
"duration": 16,
"ratio": "540p",
"cover": "https://p16-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/3a2c21cd21ad4410b8ad7ab606aa0f45_1675963028?x-expires=1709290800&x-signature=YP7J1o2kv1dLnyjv3hqwBBk487g%3D",
"playAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/e9748ee135d04a7da145838ad43daa8e/?a=1988&ch=0&cr=3&dr=0&lr=unwatermarked&cd=0%7C0%7C0%7C&cv=1&br=862&bt=431&bti=ODszNWYuMDE6&cs=0&ds=6&ft=4fUEKMUj8Zmo0Qnqi94jVZgzZpWrKsd.&mime_type=video_mp4&qs=0&rc=OzRlNzNnPDtlOTxpZjMzNkBpanFrZWk6ZmlsaTMzZzczNEAzYzI0MC1gNl8xMzUxXmE2YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709142489&l=202402281147513D9DCF4EE8518C173598&ply_type=2&policy=2&signature=c0c4220f863ca89053ec2a71b180f226&tk=tt_chain_token",
"downloadAddr": "https://v16-webapp-prime.tiktok.com/video/tos/maliva/tos-maliva-ve-0068c799-us/ed00b2ad6b9b4248ab0a4dd8494b9cfc/?a=1988&ch=0&cr=3&dr=0&lr=tiktok_m&cd=0%7C0%7C1%7C&cv=1&br=932&bt=466&bti=ODszNWYuMDE6&cs=0&ds=3&ft=4fUEKMUj8Zmo0Qnqi94jVZgzZpWrKsd.&mime_type=video_mp4&qs=0&rc=ZTs1ZTw8aTZmZzU8ZGdpNkBpanFrZWk6ZmlsaTMzZzczNEBgLmJgYTQ0NjQxYDQuXi81YSNtMjZocjRvZ2ZgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709142489&l=202402281147513D9DCF4EE8518C173598&ply_type=2&policy=2&signature=779a4044a0768f870abed13e1401608f&tk=tt_chain_token",
"bitrate": 441356
},
"author": {
"id": "6976999329680589829",
"uniqueId": "oddanimalspecimens",
"nickname": "Odd Animal Specimens",
"avatarLarger": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7327535918275887147~c5_1080x1080.jpeg?lk3s=a5d48078&x-expires=1709290800&x-signature=F8hu8G4VOFyd%2F0TN7QEZcGLNmW0%3D",
"signature": "YOUTUBE: Odd Animal Specimens\nCONTACT: OddAnimalSpecimens@whalartalent.com",
"verified": false
},
"stats": {
"diggCount": 1500000,
"shareCount": 11800,
"commentCount": 5471,
"playCount": 14000000,
"collectCount": "92420"
},
"locationCreated": "US",
"diversificationLabels": [
"Science",
"Education",
"Culture & Education & Technology"
],
"suggestedWords": [],
"contents": [
{
"textExtra": [
{
"hashtagName": "animals"
},
{
"hashtagName": "science"
},
{
"hashtagName": "learnontiktok"
}
]
}
]
}
]
The video data has been successfully collected from the TikTok website using the above scraping method. But the comments aren't there! Let's scrap it in the next part!
How To Scrape TikTok Comments?
The comment data on a post are not located in hidden fragments of the HTML code. They are incorporated quietly through concealed interfaces triggered by scroll motions.
Because a post may have thousands of comments, scraping them using a scrolling technique is virtually impossible. Thus, we will scrape them by employing the hidden comments API itself.
To locate the comments hidden API, follow the below steps:
- Right-click the computer mouse, go to the browser, tap on the developer's tools, and click on the network tab.
- Almost any video posted on TikTok by a user to a professional channel can be accessed by going to the site's web address, www.tiktok.com.
- Scroll down on the page to see more comments.
After following the above steps, you will find the API calls used for loading more comments logged:
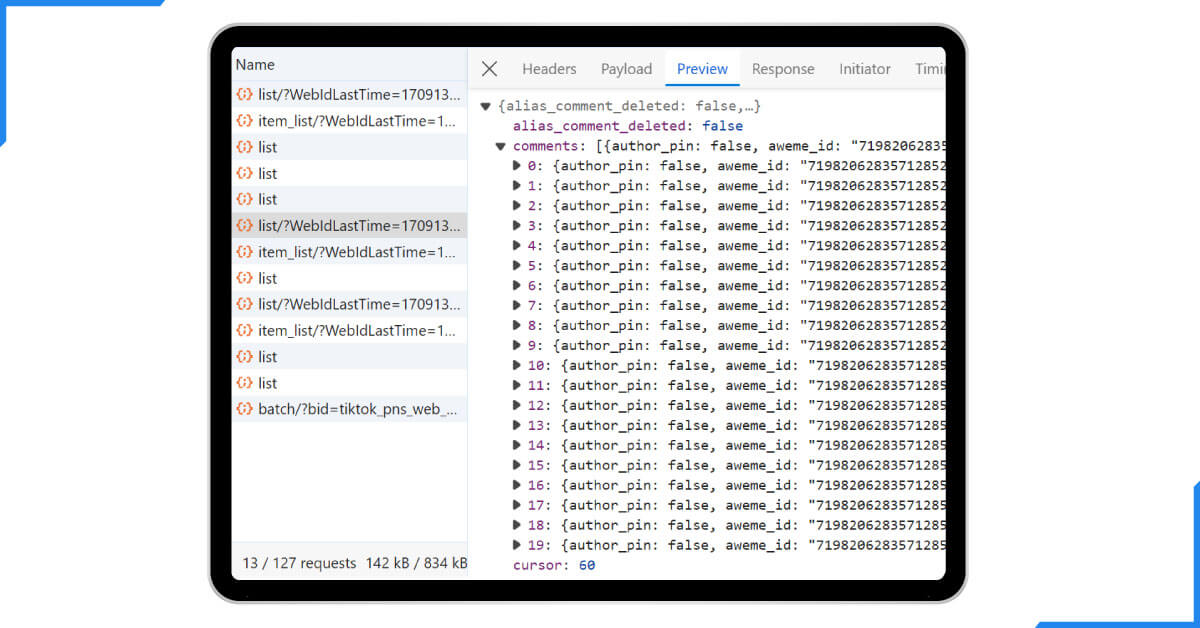
The API request was sent to the endpoint https:
It is convenient to scrape these data. This link is an example: //www. TikTok. This differentiation of API results from the, for example, com/API/comment/list/ with many different API parameters.
However, a few of them are required:
{
"aweme_id": 7198206283571285294, # the post ID
"count": 20, # number of comments to retrieve in each API call
"cursor": 0 # the index to start retrieving from
}
With the cursor claim, we'll crawl across comment pages by requesting the comments API endpoint to access the comment data directly in JSON:
import jmespath
import asyncio
import json
from urllib.parse import urlencode
from typing import List, Dict
from httpx import AsyncClient, Response
from loguru import logger as log
# initialize an async httpx client
client = AsyncClient(
# enable http2
http2=True,
# add basic browser like headers to prevent being blocked
headers={
"Accept-Language": "en-US,en;q=0.9",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"content-type": "application/json"
},
)
def parse_comments(response: Response) -> List[Dict]:
"""parse comments data from the API response"""
data = json.loads(response.text)
comments_data = data["comments"]
total_comments = data["total"]
parsed_comments = []
# refine the comments with JMESPath
for comment in comments_data:
result = jmespath.search(
"""{
text: text,
comment_language: comment_language,
digg_count: digg_count,
reply_comment_total: reply_comment_total,
author_pin: author_pin,
create_time: create_time,
cid: cid,
nickname: user.nickname,
unique_id: user.unique_id,
aweme_id: aweme_id
}""",
comment
)
parsed_comments.append(result)
return {"comments": parsed_comments, "total_comments": total_comments}
async def scrape_comments(post_id: int, comments_count: int = 20, max_comments: int = None) -> List[Dict]:
"""scrape comments from tiktok posts using hidden APIs"""
def form_api_url(cursor: int):
"""form the reviews API URL and its pagination values"""
base_url = "https://www.tiktok.com/api/comment/list/?"
params = {
"aweme_id": post_id,
'count': comments_count,
'cursor': cursor # the index to start from
}
return base_url + urlencode(params)
log.info("scraping the first comments batch")
first_page = await client.get(form_api_url(0))
data = parse_comments(first_page)
comments_data = data["comments"]
total_comments = data["total_comments"]
# get the maximum number of comments to scrape
if max_comments and max_comments < total_comments:
total_comments = max_comments
# scrape the remaining comments concurrently
log.info(f"scraping comments pagination, remaining {total_comments // comments_count - 1} more pages")
_other_pages = [
client.get(form_api_url(cursor=cursor))
for cursor in range(comments_count, total_comments + comments_count, comments_count)
]
for response in asyncio.as_completed(_other_pages):
response = await response
data = index.html
comments_data.extend(data)
log.success(f"scraped {len(comments_data)} from the comments API from the post with the ID {post_id}")
return comments_data
The above code scrapes TikTok comments data using two main functions:
- scrape_comments: To construct the comments API URL for the desired forum in a way that incorporates the offset of comments and makes a get request to obtain the comment data in the JSON format.
- parse_comments: This one specifies how the comments API responses should be parsed to get valuable data using JMESPath.
Here is a sample output of the comment data we got:
[
{
"text": "Dude give ‘em back",
"comment_language": "en",
"digg_count": 72009,
"reply_comment_total": 131,
"author_pin": false,
"create_time": 1675963633,
"cid": "7198208855277060910",
"nickname": "GrandMoffJames",
"unique_id": "grandmoffjames",
"aweme_id": "7198206283571285294"
},
{
"text": "Dudes got everyone’s back",
"comment_language": "en",
"digg_count": 36982,
"reply_comment_total": 100,
"author_pin": false,
"create_time": 1675966520,
"cid": "7198221275168719662",
"nickname": "Scott",
"unique_id": "troutfishmanjr",
"aweme_id": "7198206283571285294"
},
{
"text": "do human backbone",
"comment_language": "en",
"digg_count": 18286,
"reply_comment_total": 99,
"author_pin": false,
"create_time": 1676553505,
"cid": "7200742421726216987",
"nickname": "www",
"unique_id": "ksjekwjkdbw",
"aweme_id": "7198206283571285294"
},
{
"text": "casually has a backbone in his inventory",
"comment_language": "en",
"digg_count": 20627,
"reply_comment_total": 9,
"author_pin": false,
"create_time": 1676106562,
"cid": "7198822535374734126",
"nickname": "*",
"unique_id": "angelonextdoor",
"aweme_id": "7198206283571285294"
},
{
"text": "😧",
"comment_language": "",
"digg_count": 7274,
"reply_comment_total": 20,
"author_pin": false,
"create_time": 1675963217,
"cid": "7198207091995132698",
"nickname": "Son Bi’",
"unique_id": "son_bisss",
"aweme_id": "7198206283571285294"
},
....
The TikTok scraper code mentioned above only takes seconds to gather tens of comments. This is because using the TikTok secret APIs for site scraping is far quicker than processing HTML data.
How To Scrape TikTok Search Data?
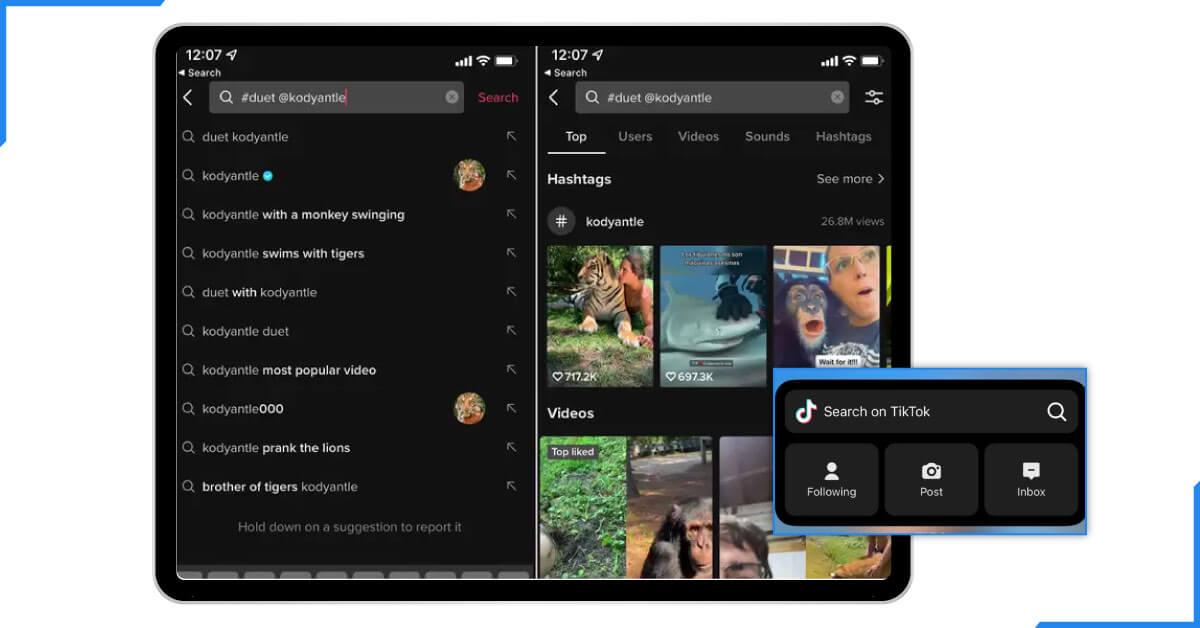
In this section, we'll proceed with the last piece of our TikTok web scraping code: any search engine web pages. Let's illustrate specific pages of the popular Yahoo, Google, and MSN search engines. The search data are loaded through a hidden API that will be used for web scraping. However, the search page data can also be grabbed from background XHR calls, which we used to scrape the channel data.
To capture the search API, follow the below steps:
- Develop the browser and click on the network tab at the top of the developed browser.
- Click in the search box to type in any keyword of your choice.
- Get to the bottom and press on the load more to expand the search results obtained.
After following the above steps, you will find the search API requests logged:
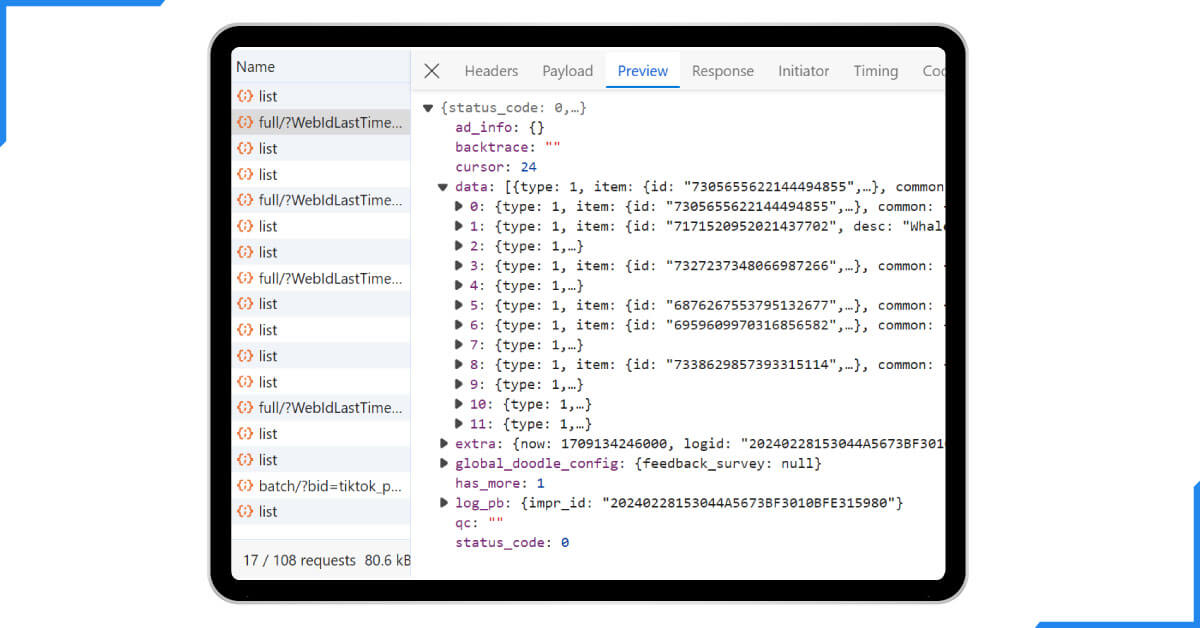
The following endpoint received the API mentioned above call with the following parameters:
search_api_url = "https://www.tiktok.com/api/search/general/full/?"
parameters = {
"keyword": "whales", # the keyword of the search query
"offset": cursor, # the index to start from
"search_id": "2024022710453229C796B3BF936930E248" # timestamp with random ID
}
The search query requires the inputs above. However, this endpoint needs specific cookie settings to authorize the requests, which might be challenging to manage.
Therefore, in order to retrieve a cookie and reuse it with the search API calls, we'll take advantage of the specific sessions feature:
import datetime
import secrets
import asyncio
import json
import jmespath
from typing import Dict, List
from urllib.parse import urlencode, quote
from loguru import logger as log
from scrapfly import ScrapeConfig, ScrapflyClient, ScrapeApiResponse
SCRAPFLY = ScrapflyClient(key="Your Scrapfly API key key")
def parse_search(response: ScrapeApiResponse) -> List[Dict]:
"""parse search data from the API response"""
data = json.loads(response.scrape_result["content"])
search_data = data["data"]
parsed_search = []
for item in search_data:
if item["type"] == 1: # get the item if it was item only
result = jmespath.search(
"""{
id: id,
desc: desc,
createTime: createTime,
video: video,
author: author,
stats: stats,
authorStats: authorStats
}""",
item["item"]
)
result["type"] = item["type"]
parsed_search.append(result)
# wheter there is more search results: 0 or 1. There is no max searches available
has_more = data["has_more"]
return parsed_search
async def obtain_session(url: str) -> str:
"""create a session to save the cookies and authorize the search API"""
session_id="tiktok_search_session"
await SCRAPFLY.async_scrape(ScrapeConfig(
url, asp=True, country="US", render_js=True, session=session_id
))
return session_id
async def scrape_search(keyword: str, max_search: int, search_count: int = 12) -> List[Dict]:
"""scrape tiktok search data from the search API"""
def generate_search_id():
# get the current datetime and format it as YYYYMMDDHHMMSS
timestamp = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
# calculate the length of the random hex required for the total length (32)
random_hex_length = (32 - len(timestamp)) // 2 # calculate bytes needed
random_hex = secrets.token_hex(random_hex_length).upper()
random_id = timestamp + random_hex
return random_id
def form_api_url(cursor: int):
"""form the reviews API URL and its pagination values"""
base_url = "https://www.tiktok.com/api/search/general/full/?"
params = {
"keyword": quote(keyword),
"offset": cursor, # the index to start from
"search_id": generate_search_id()
}
return base_url + urlencode(params)
log.info("obtaining a session for the search API")
session_id = await obtain_session(url="https://www.tiktok.com/search?q=" + quote(keyword))
log.info("scraping the first search batch")
first_page = await SCRAPFLY.async_scrape(ScrapeConfig(
form_api_url(cursor=0), asp=True, country="US", session=session_id
))
search_data = parse_search(first_page)
# scrape the remaining comments concurrently
log.info(f"scraping search pagination, remaining {max_search // search_count} more pages")
_other_pages = [
ScrapeConfig(form_api_url(cursor=cursor), asp=True, country="US", session=session_id
)
for cursor in range(search_count, max_search + search_count, search_count)
]
async for response in SCRAPFLY.concurrent_scrape(_other_pages):
data = parse_search(response)
search_data.extend(data)
log.success(f"scraped {len(search_data)} from the search API from the keyword {keyword}")
return search_data
Let's break down the execution flow of the above TikTok scraping code:
- Another request is made to the usual search page to get the cookie values using the obtain_session function.
- Using the method generate_search_id, one random search ID is created and then used with the requests to the search API.
- The first search API URL is constructed with the help of the form_api_url function.
- A request is made to the search API, where the session key with the cookies is passed.
- The search API's JSON response is parsed to the parse_search function. The response data is also filtered to finally provide only video data.
The above code obtains search results for profile and video data using the /search/general/full API. This endpoint only supports a low cursor value. Filters to focus the results may effectively manage its pagination.
This is a sample output of the outcomes we obtained:
[
{
"id": "7192262480066825515",
"desc": "Replying to @julsss1324 their songs are described as hauntingly beautiful. Do you find them scary or beautiful? For me it’s peaceful. They remind me of elephants. 🐋🎶💙 @kaimanaoceansafari #whalesounds #whalesong #hawaii #ocean #deepwater #deepsea #thalassophobia #whales #humpbackwhales ",
"createTime": 1674579130,
"video": {
"id": "7192262480066825515",
"height": 1024,
"width": 576,
"duration": 25,
"ratio": "540p",
"cover": "https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/e438558728954c74a761132383865d97_1674579131~tplv-dmt-logom:tos-useast5-i-0068-tx/0bb4cf51c9f445c9a46dc8d5aab20545.image?x-expires=1709215200&x-signature=Xl1W9ELtZ5%2FP4oTEpjqOYsGQcx8%3D",
"originCover": "https://p19-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/2061429a4535477686769d5f2faeb4f0_1674579131?x-expires=1709215200&x-signature=OJW%2BJnqnYt4L2G2pCryrfh52URI%3D",
"dynamicCover": "https://p19-sign.tiktokcdn-us.com/obj/tos-useast5-p-0068-tx/88b455ffcbc6421999f47ebeb31b962b_1674579131?x-expires=1709215200&x-signature=hDBbwIe0Z8HRVFxLe%2F2JZoeHopU%3D",
"playAddr": "https://v16-webapp-prime.us.tiktok.com/video/tos/useast5/tos-useast5-pve-0068-tx/809fca40201048c78299afef3b627627/?a=1988&ch=0&cr=3&dr=0&lr=unwatermarked&cd=0%7C0%7C0%7C&cv=1&br=3412&bt=1706&bti=NDU3ZjAwOg%3D%3D&cs=0&ds=6&ft=4KJMyMzm8Zmo0apOi94jV94rdpWrKsd.&mime_type=video_mp4&qs=0&rc=NDU3PDc0PDw7ZGg7ODg0O0BpM2xycGk6ZnYzaTMzZzczNEBgNl4tLjFiNjMxNTVgYjReYSNucGwzcjQwajVgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709216449&l=202402271420230081AD419FAC9913AB63&ply_type=2&policy=2&signature=1d44696fa49eb5fa609f6b6871445f77&tk=tt_chain_token",
"downloadAddr": "https://v16-webapp-prime.us.tiktok.com/video/tos/useast5/tos-useast5-pve-0068-tx/c7196f98798e4520834a64666d253cb6/?a=1988&ch=0&cr=3&dr=0&lr=tiktok_m&cd=0%7C0%7C1%7C&cv=1&br=3514&bt=1757&bti=NDU3ZjAwOg%3D%3D&cs=0&ds=3&ft=4KJMyMzm8Zmo0apOi94jV94rdpWrKsd.&mime_type=video_mp4&qs=0&rc=ZTw5Njg0NDo3Njo7PGllOkBpM2xycGk6ZnYzaTMzZzczNEBhYjFiLjA1NmAxMS8uMDIuYSNucGwzcjQwajVgLS1kMS9zcw%3D%3D&btag=e00088000&expire=1709216449&l=202402271420230081AD419FAC9913AB63&ply_type=2&policy=2&signature=1443d976720e418204704f43af4ff0f5&tk=tt_chain_token",
"shareCover": [
"",
"https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/2061429a4535477686769d5f2faeb4f0_1674579131~tplv-photomode-tiktok-play.jpeg?x-expires=1709647200&x-signature=%2B4dufwEEFxPJU0NX4K4Mm%2FPET6E%3D",
"https://p16-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/2061429a4535477686769d5f2faeb4f0_1674579131~tplv-photomode-share-play.jpeg?x-expires=1709647200&x-signature=XCorhFJUTCahS8crANfC%2BDSrTbU%3D"
],
"reflowCover": "https://p19-sign.tiktokcdn-us.com/tos-useast5-p-0068-tx/e438558728954c74a761132383865d97_1674579131~tplv-photomode-video-cover:480:480.jpeg?x-expires=1709215200&x-signature=%2BFN9Vq7TxNLLCtJCsMxZIrgjMis%3D",
"bitrate": 1747435,
"encodedType": "normal",
"format": "mp4",
"videoQuality": "normal",
"encodeUserTag": ""
},
"author": {
"id": "6763395919847523333",
"uniqueId": "mermaid.kayleigh",
"nickname": "mermaid.kayleigh",
"avatarThumb": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7310953622576037894~c5_100x100.jpeg?lk3s=a5d48078&x-expires=1709215200&x-signature=0tw66iTdRDhPA4pTHM8e4gjIsNo%3D",
"avatarMedium": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7310953622576037894~c5_720x720.jpeg?lk3s=a5d48078&x-expires=1709215200&x-signature=IkaoB24EJoHdsHCinXmaazAWDYo%3D",
"avatarLarger": "https://p16-sign-va.tiktokcdn.com/tos-maliva-avt-0068/7310953622576037894~c5_1080x1080.jpeg?lk3s=a5d48078&x-expires=1709215200&x-signature=38KCawETqF%2FdyMX%2FAZg32edHnc4%3D",
"signature": "Love the ocean with me 💙\nOwner @KaimanaOceanSafari 🤿\nCome dive with me👇🏼",
"verified": true,
"secUid": "MS4wLjABAAAAhIICwHiwEKwUg07akDeU_cnM0uE1LAGO-kEQdw3AZ_Rd-zcb-qOR0-1SeZ5D2Che",
"secret": false,
"ftc": false,
"relation": 0,
"openFavorite": false,
"commentSetting": 0,
"duetSetting": 0,
"stitchSetting": 0,
"privateAccount": false,
"downloadSetting": 0
},
"stats": {
"diggCount": 10000000,
"shareCount": 390800,
"commentCount": 72100,
"playCount": 89100000,
"collectCount": 663400
},
"authorStats": {
"followingCount": 313,
"followerCount": 2000000,
"heartCount": 105400000,
"videoCount": 1283,
"diggCount": 40800,
"heart": 105400000
},
"type": 1
},
....
]
How to Avoid Blocking From TikTok Website?
Bypassing TikTok's scraping-blocking mechanisms involves several advanced techniques and considerations.
Use Rotating Proxies
Rotating proxies obtain new IPs for every request, making it tricky for TikTok to identify multiple requests from the same source. Other services, such as Bright Data or ScraperAPI, offer pools of IP addresses that shift with each request or at set times, which aids in not getting recognized.
Adjust Request Headers
HTTP headers carry information about the request being made. Changing headers to mimic a typical browser can reduce the chances of being detected. Necessary headers to modify include User-Agent (browser type), Accept-Language (language preferences), Referer (previous page), and Cookies (session data). Libraries like requests in Python or Axios in JavaScript can help customize these headers.
Implement Rate Limiting
Sending requests too quickly can trigger TikTok’s rate-limiting mechanisms. Introducing delays between requests, using functions like time and sleep() in Python, can make the scraping activity look more like normal user behavior and avoid detection.
Randomize Request Intervals
Instead of sending requests at fixed intervals, randomize the timing to prevent easily detected patterns. Use functions like random.uniform() to vary the sleep intervals between requests, making the activity seem more natural.
Use Headless Browsers
It does not open a graphical user interface to display the website visually; other tools like Puppeteer and Selenium are headless browsers. There is nothing JavaScript cannot render here, and these tools are, therefore, suitable for dynamic sites like TikTok.
Solve CAPTCHAs
TikTok may use CAPTCHAs to verify if a user is human. Automated CAPTCHA-solving services like 2Captcha or Anti-Captcha can be integrated into your scraping script to handle these challenges. However, this method can add extra costs and might have limitations.
Monitor for Changes
TikTok frequently updates its website and anti-scraping measures. Regularly reviewing TikTok’s HTML structure and JavaScript code helps keep your scraping tool functional. Adapting your scripts to these changes ensures continued success in data extraction.
Leverage Public APIs
Official or third-party APIs offer structured data access without violating terms of service. APIs are designed for reliable and ethical data retrieval, but they may have usage limits and might not provide access to all data available on the website. Using APIs is a more dependable approach for gathering information.
Conclusion
The information that is collected from TikTok scraping could be helpful. For instance, it can help companies understand which video categories are performing well and guide them in producing the materials their target audience finds most appealing. Researchers on social behavior or trends could analyze the data, and marketers can see trending hashtags and influential personalities to use in their campaigns. In other words, it assists in transforming the overwhelming volume of data available in TikTok into beneficial data.
Scraping without permission may be against the contract that TikTok has with its users and attract the attention of the law. It can also cause privacy issues as people may not be aware that they are inserting information into the network, and this information will be used to analyze their behavior. To solve such issues, several regulations, general privacy concerns, and perhaps obtaining the user’s permission before scraping should be considered. Adhering to ethical practices assists in maintaining people’s confidence and stopping possible abuse of the gathered data.
Headquarter
10685-B Hazelhurst Dr.#23604 Houston,TX 77043 USA
Incredible Solutions After Consultation
- → Industry Specific Expert Opinion
- → Assistance in Data-Driven Decision Making
- → Insights Through Data Analysis




