Zillow is regarded as one of the leading real estate companies in the United States, for it has a variety of housing listings, including homes for sale, rent, and those not on the market. Zillow was established in 2006 as a popular online real estate platform for home buyers, renters, and real estate professionals. It has a search interface where users can search for properties by location, price range, property type, and trends. Zillow is an excellent tool for anyone in the real estate market, given the company’s large audience and the range of information it has at its disposal.
Zillow has several unique selling points, including the Zestimate tool, which provides information on the market value of homes and lots using data collected from the public domain and information supplied by users. Although Zestimate is not an actual property appraisal, it helps set an essential value for the user. Zillow also provides several features for estimating monthly house payments with home loans, monitoring rental prices, and more, making the website a comprehensive guide to properties and real estate.
What is Zillow Data Scraping?
Zillow data scraping is the collection of data on various properties across the United States from Zillow, a real estate website. This comprises scraping data from the Zillow property listing interface, including price, address, and property descriptions, among others, by capturing the HTML content of Zillow. Web scraping allows you to obtain vast amounts of information on real estate without copying the data manually, which takes a lot of time.
Real estate agents, investors, and analysts conduct Zillow web scraping to analyze the housing market, evaluate promising deals, and understand apartment rates. However, it should also be noted that HOs can fall into legal and ethical grey areas of web scraping, and as mentioned, Zillow has terms of service banning such data harvesting. Scraping Zillow data requires considering these guidelines carefully and, when possible, opting to use the Zillow API or licensed data services.
Advantages of Real Estate Data Scraping
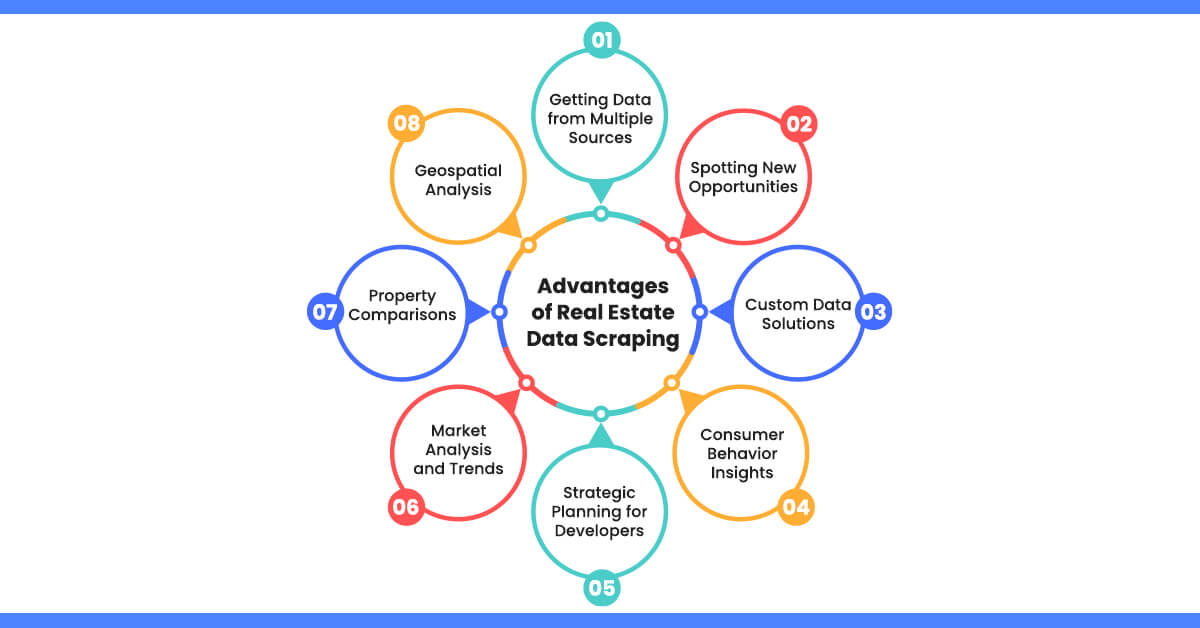
The Zillow data scraper assists in obtaining large datasets from websites and enables the gathering of significant amounts of information from various sources.
Getting Data from Multiple Sources
Gathering data from various sources requires processing and refine the datasets to ensure smooth analysis processes. That is why copy-paste from such sources as listing sites, property portals, and individual agent websites is reasonable. Doing this will provide you with a better and more detailed perspective on what is really happening in the real estate market.
Spotting New Opportunities
Real estate data scraping can also increase opportunities and make the right choices. For instance, investors can use scraped data to research properties that are either undervalued or overpriced. Along the same line, scraped details can be used to set appropriate prices and create other marketing strategies based on genuine listings.
Custom Data Solutions
People can scrape the data to create a particular set of reports and graphs that will serve the user's purpose, whether the user is an individual, a businessman, or even a client reports. The scraped data can be used for big data and data mining techniques to make predictions about the future value of properties or the market, for instance.
Consumer Behavior Insights
One can identify consumer opinions and trends by web scraping the number of visits, favorites, and shares of the listings. Based on such results, users can see fluctuations over a period of time in buying, selling, and even renting.
Strategic Planning for Developers
Developers can use this scraped data to determine the market feasibility of a new project by analyzing the trend and competition of properties in certain sections. Identifying the price ranges of similar properties assists in setting appropriate prices for new properties.
Market Analysis and Trends
Using Zillow data scraping, people can get acquainted with the changes in a property’s price fluctuations over time depending on the area in which it is located, which enhances a real estate investor’s decision-making process. The statistics given by the website regarding the number of clicks or times a listing has been saved can be an excellent pointer towards the popularity or need for homes or apartments in specific locations.
Property Comparisons
The Zillow website offers the publication's history, the building's characteristics, the history of its price, the characteristics of the neighborhood, and many more. Users can easily search for required properties in preferred areas and compare them simultaneously.
Geospatial Analysis
Zillow gives viewers information on the facilities, schools, security, and other factors that can be very important in choosing a house. This data can be scraped to allow for more profound geospatial data analysis. Heat maps and other such graphs may be developed with the help of aggregated data to analyze the market trends and identify the areas of high interest for properties.
Real Estate data Scraping challenges
Web scraping real estate websites is not free from issues and hurdles. Here are some common obstacles:
Complex Web Layouts
Property websites often have complex and evolving design patterns, which make them challenging to scrape. This might lead to unstructured data, which must be rectified manually.
Anti-Scraping Technologies
Restrictions to scraping implemented in property websites include the use of scripting languages like JavaScript, Asynchronous JavaScript, and XML (AJAX) and the Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA). These can prevent you from obtaining the data you need or, worse, get your IP address blocked. These require specific workarounds.
Data Quality Issues
Real estate prices may fluctuate, and it is possible to gather a lot of information only to find that it is outdated information collected from the field. So, it is important to process and filter the data collected for better analysis.
Legal Concerns
The legality of web scraping is a disputed issue, even on real estate sites. Scraping freely available data is usually safe; however, if it is copyrighted, you must be cautious. Seeking advice from a legal professional is an ideal way to make sure you're not breaking any laws. Speaking with a legal professional to verify you're not breaking any rules.
How to Scrape Zillow Website Data?
This step-by-step guide helps you scrape address, prices, real estate providers, and URLs.
Install packages to scrape Zillow data.
Requests and lxml are external Python libraries that must be installed with pip.
pip install lxml requests
Installing the Unicodecsv library is also necessary if you want to write CSV files.
pip install unicodecsv
Scrape Zillow Website
Below is the Python code for scraping Zillow data. First, import the required libraries and modules.
from lxml import html import requests import unicodecsv as csv import argparse import json
The information extracted can include redundant white space. S,o create a method clean() to eliminate any such gaps.
def clean(text):
if text
return ' '.join(' '.join(text).split())
return None
To keep things organized, keep headers distinct from other functions. You may use this function to retrieve the headers. This method also makes it easier to update headers because you don't have to alter the core code.
def get_headers():
# Creating headers.
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
return headers
The code can organize the results by either the cheapest or newest. If no sort option is used, it may return unsorted listings.
These cases necessitate a different request URL when scraping Zillow data using Python lxml. Define a create_url function that returns the correct URL depending on the criteria.
def create_url(zipcode, filter):
# Creating Zillow URL based on the filter.
if filter == "newest":
url = "https://www.zillow.com/homes/for_sale/{0}/0_singlestory/days_sort".format(zipcode)
elif filter == "cheapest":
url = "https://www.zillow.com/homes/for_sale/{0}/0_singlestory/pricea_sort/".format(zipcode)
else:
url = "https://www.zillow.com/homes/for_sale/{0}_rb/?fromHomePage=true&shouldFireSellPageImplicitClaimGA=false&fromHomePageTab=buy".format(zipcode)
print(url)
return url
To troubleshoot a problem, you may need to review the answer text. Create a method save_to_file() that saves the response to a file.
def save_to_file(response):
# saving response to `response.html`
with open("response.html", 'w', encoding="utf-8") as fp:
fp.write(response.text)
Clarify a function. Use the write_data_to_csv function to save the extracted data to a CSV file.
def write_data_to_csv(data):
# saving scraped data to csv.
with open("properties-%s.csv" % (zipcode), 'wb') as csvfile:
fieldnames = ['address', 'price','real estate provider', 'url']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for row in data:
writer.writerow(row)
To retrieve the result, create a get_response() method that sends an HTTP call to Zillow.com. The method also calls save_to_file(), which saves the response to a file.
def get_response(url):
# Getting response from zillow.com.
for i in range(5):
response = requests.get(url, headers=get_headers())
print("status code received:", response.status_code)
if response.status_code != 200:
# saving response to file for debugging purpose.
save_to_file(response)
continue
else:
save_to_file(response)
return response
return None
Create a parse() function that integrates.
create_url(),
get_response(),
clean(),
and return a list of Zillow properties.
The parse() method parses the response text using lxml. It then used XPath to find HTML elements in the response and extract the relevant data.
def parse(zipcode, filter=None):
url = create_url(zipcode, filter)
response = get_response(url)
if not response:
print("Failed to fetch the page, please check `response.html` to see the response received from zillow.com.")
return None
parser = html.fromstring(response.text)
search_results = parser.xpath("//div[@id='grid-search-results']//article")
print(search_results)
print("parsing from html page")
properties_list = []
for properties in search_results:
raw_address = properties.xpath(".//address//text()")
raw_price = properties.xpath(".//span[@class='PropertyCardWrapper__StyledPriceLine-srp__sc-16e8gqd-1 iMKTKr']//text()")
raw_broker_name = properties.xpath(".//div[@class='StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jretvB']//text()")
url = properties.xpath(".//a[@class='StyledPropertyCardDataArea-c11n-8-84-3__sc-yipmu-0 jnnxAW property-card-link']/@href")
raw_title = properties.xpath(".//h4//text()")
address = clean(raw_address)
price = clean(raw_price)
#info = clean(raw_info).replace(u"\xb7", ',')
broker = clean(raw_broker_name)
title = clean(raw_title)
property_url = "https://www.zillow.com" + url[0] if url else None
properties = {'address': address,
'price': price,
'real estate provider': broker,
'url': property_url,
}
print(properties)
properties_list.append(properties)
return properties_list
Finally, use the parse() method and write_data_to_csv() to save the retrieved property listings as a CSV file.
if __name__ == "__main__":
# Reading arguments
argparser = argparse.ArgumentParser(formatter_class=argparse.RawTextHelpFormatter)
argparser.add_argument('zipcode', help='')
sortorder_help = """
available sort orders are :
newest : Latest property details,
cheapest : Properties with cheapest price
"""
argparser.add_argument('sort', nargs='?', help=sortorder_help, default='Homes For You')
args = argparser.parse_args()
zipcode = args.zipcode
sort = args.sort
print ("Fetching data for %s" % (zipcode))
scraped_data = parse(zipcode, sort)
if scraped_data:
print ("Writing data to output file")
write_data_to_csv(scraped_data)
The code also uses the argparse module to offer the script command-line capability. That is how you specify the ZIP code and sorting choice to the script.
Here is a flowchart illustrating the execution order of the functions provided for web scraping Zillow using Python.
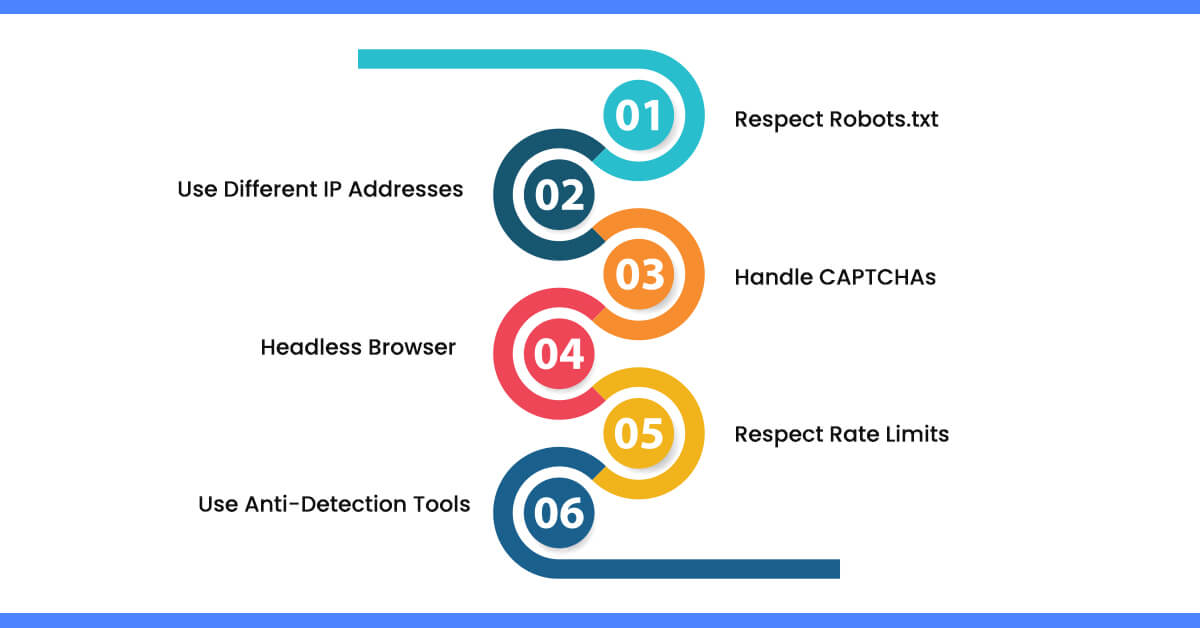
How Do You Scrape Zillow Data Without Getting Blocked?
In general, web scraping Zillow can effectively collect real estate data, but it must be done as carefully as possible to avoid blocking.
Respect Robots.txt
In this case, the rules governing web scraping limit which portions of the Zillow website can be accessed with a bot and which sections cannot be accessed. These rules are in a file named robots.txt. If you are ready to scrape, check the robots of Zillow first. To make sure which pages are allowed or not you need to read the ‘robots.txt’ file of the website. Ensure that you do not scratch these restricted areas so that you do not overstep their bounds.
Use Different IP Addresses
In this case, the rules governing web scraping limit which portions of the Zillow website can be accessed with a bot and which sections cannot be accessed. These rules are in a file named robots.txt. If you are ready to scrape, check the robots of Zillow first. To make sure which pages are allowed or not you need to read the ‘robots.txt’ file of the website. Ensure that you do not scratch these restricted areas so that you do not overstep their bounds.
Handle CAPTCHAs
Sometimes, Zillow and similar online platforms may ask you to complete a CAPTCHA test to check if you are human. CAPTCHAs are those questions or tasks one must accomplish to verify that the individual is not a computer. If you find CAPTCHAs, you can go for a service that will solve them on your behalf. The best way to avoid them is to try not to make them in the first place by scraping gently and mimicking the program's expected usage.
Headless Browser
A headless browser is a kind of browser that can navigate the Web and interact with it, but it does not render any UI on the screen. It works as one would expect a browser to work, but you have a programming interface to manipulate it. Scrape Zillow data by using tools such as Puppeteer or Selenium.
Respect Rate Limits
Some websites will limit the number of requests you can make in some given time. Indeed, if your rate is within this limit, you may be blocked. Try to focus on the number of requests you are sending and do not exceed any restriction set by Zillow. You should also observe that there is a problem if you find yourself blocked after you have made several requests; just slow down and make fewer requests.
Use Anti-Detection Tools
Some tools and libraries help hide the fact that you’re scraping from Zillow’s detection systems. Use anti-detection plugins or libraries to make your requests look more like a real user’s activity. For example, these tools might disable certain browser features that Zillow could use to detect bots.
Conclusion
In addition to listings, Zillow has ventured into Zillow Offers, where homeowners are offered cash for their homes. Zillow Home Loans with mortgage services are provided through the platform to ensure easy accessibility. Websites like Zillow might give you warnings before entirely blocking you, like showing you an error message. Look for error messages like “403 Forbidden” or “429 Too Many Requests.” Some tools and libraries help hide the fact that you’re scraping from Zillow’s detection systems. Use anti-detection plugins or libraries to make your requests look more like a real user’s activity. For example, these tools might disable certain browser features that Zillow could use to detect bots. If you always scrape the same data in the same order, it’s easier for Zillow to recognize and block your pattern. For example, don’t always scrape the same data type or visit pages in the same order. Randomly choose what data to collect and the paths you take through the website.
Headquarter
10685-B Hazelhurst Dr.#23604 Houston,TX 77043 USA
Incredible Solutions After Consultation
- → Industry Specific Expert Opinion
- → Assistance in Data-Driven Decision Making
- → Insights Through Data Analysis




