So, you’re looking for a job and would like to work smarter instead of harder to find something new and interesting? Why not create a web scraper that will gather and analyze job posting data for you?
Analyzing the URL and Page structure
Firstly, we will need to look at the demo page from indeed.
There are a few things to note regarding the URL structure:
- Note that “q=” starts the text for the “what” field on the page, with “+” separating search terms (e.g., looking for “data+scientist” jobs).
- While mentioning salary, it will sort by commas in the salary amount, so the initial stage of the salary will be preceded by %24 and the figure before the first comma, it will then be broken by %2C and will continue with the other numbers (i.e., %2420%2C000 = $20,000).
- Note that the string for the city of concern begins with “&l=,” with “+” separating search phrases if the city is more than one word (i.e., “New+York”).
- “&start=” is a placeholder for the results page wherever you want to start (i.e., start by looking at the 10th result)
As we develop a scraper to look at and collect information from a succession of pages, the URL structure will be helpful. Keep this in mind for future reference.
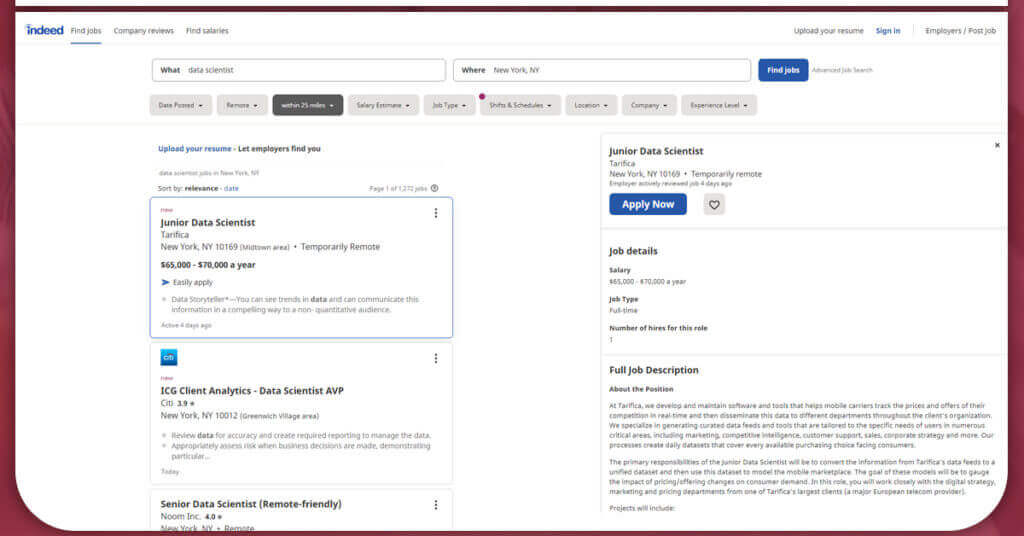
Each page will display 15 job posts, from which five are “sponsored” jobs, which are especially highlighted by indeed outside of normal order of results. The other 10 results are specified on the page that are viewed.
HTML tags are used to code all the information on this page. HTML (Hyper Text Markup Language) is the script that will tell your browser about displaying the content of a particular page during visiting. This will contain the general structure and organization of the document. HTML elements also include attributes, which help in keeping track of what information may be located where on a page’s structure.
By right-clicking on a page and selecting “Inspect” from the menu that shows, Chrome users can inspect the HTML structure of the page. On the right-hand side of your website, a menu will emerge, with a long line of stacked HTML tags containing the data now visible in your web browser.
There’s a small box with an arrow icon in the upper-left corner of this menu. The box will turn blue when you click it. This will start to move your mouse over the page elements to see that both the tags associated with that item and the location of that item are in the HTML format for that page.
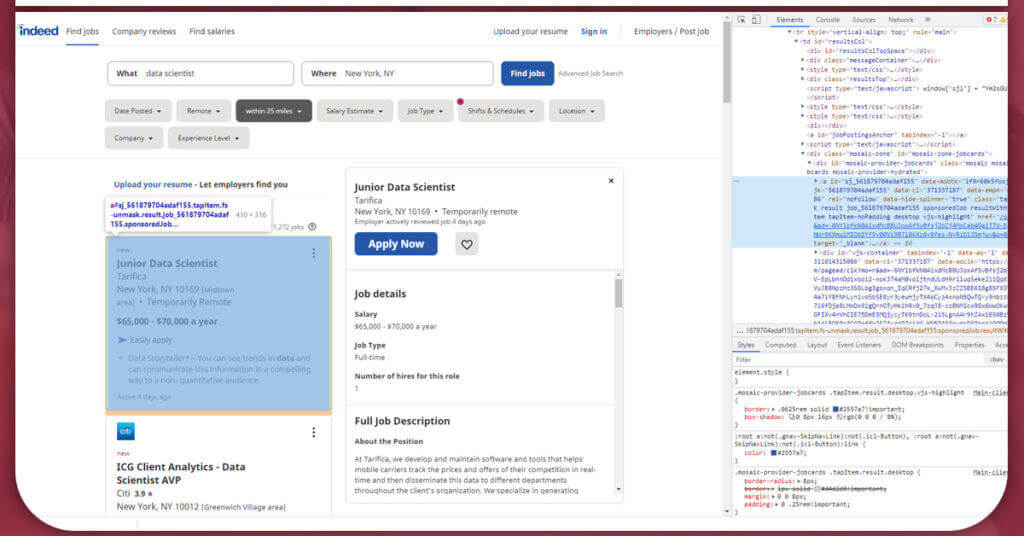
In the screenshot shared above, we gave pointed one of the jobs posting, that shows how the entire jobs is placed between a <div> tag, with attributes that include “class=’row result”’, “id= “id=’pj_7a21e2c11afb0428’”, etc., Fortunately, we won’t need to know every characteristic of every element to retrieve our data, but knowing how to understand a page’s HTML structure will come in handy.
Now we’ll use Python to retrieve the Xml from the page and start working on our scraper.
Connecting the Scraper Components
import requests import bs4 from bs4 import Beautiful Soup import pandas as pd import time
Let’s start by extracting a single page and figuring out the code to get each piece of data we need:
URL = “https://www.indeed.com/jobs?q=data+scientist+%2420%2C000&l=New+York&start=10"#conducting a request of the stated URL above: page = requests.get(URL)#specifying a desired format of “page” using the html parser - this allows python to read the various components of the page, rather than treating it as one long string. soup = BeautifulSoup(page.text, “html.parser”)#printing soup in a more structured tree format that makes for easier reading print(soup.prettify())
It is much easier to visit a page’s HTML coding with prettify, and you’ll get something like this:

Looking over to the task, we will search and scrape five important use cases of information from every job posting: Job Title, Company Name, Location, Salary, and Job Summary.
Job Title
As said above, each job posting comes under <div> tags, with an attribute “class” = “row result”.
From there, the job titles will be listed under <a> tags, with the attribute “title = (title)”. We can search the value of a tag’s attribute with tag[“attribute”], so I can use it to search the job title for every job posting.
Script for withdrawing job title data takes three steps:
- Pulling out all <div> tags with the class that includes “row”.
- Identifying <a> tags with the attribute “data-tn-element’: ‘Job Title”.
- For every <a> tag, find the value of the attribute’s “title”.
def extract_job_title_from_result(soup):
jobs = []
for div in soup.find_all(name=”div”, attrs={“class”:”row”}):
for a in div.find_all(name=”a”, attrs={“data-tn-element”:”jobTitle”}):
jobs.append(a[“title”])
return(jobs)extract_job_title_from_result(soup)
This will display an output like:

Company Name
Company names are a bit complicated, as they appear in <span> tags, including “class”:”company”. Moreover, they will be included in <span> tags with “class”:”result-link-source’.
def extract_company_from_result(soup):
companies = []
for div in soup.find_all(name=”div”, attrs={“class”:”row”}):
company = div.find_all(name=”span”, attrs={“class”:”company”})
if len(company) > 0:
for b in company:
companies.append(b.text.strip())
else:
sec_try = div.find_all(name=”span”, attrs={“class”:”result-link-source”})
for span in sec_try:
companies.append(span.text.strip())
return(companies)
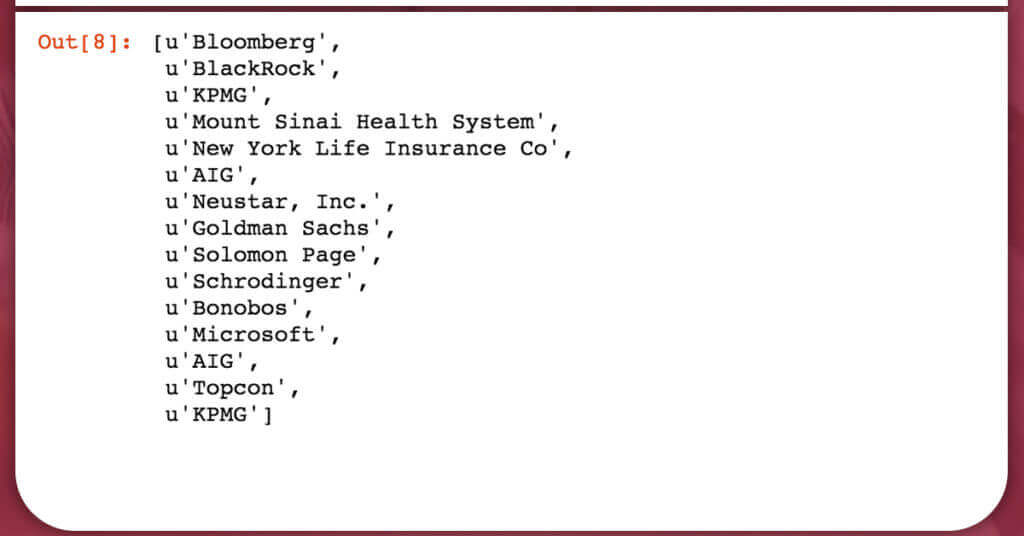
extract_company_from_result(soup)
Output of company names are displayed with a lot of white spaces around them, so inputting.strip() at the end will help to delete this while fetching the data.
Location
Location comes under the <span> tags. Many times, span tags are connected, in such a manner that the location text will sometimes be within “class”: “location” attributes, or nested in the “itemprop”: “addresslocality”.
However, a simple script of the loop can monitor all the span tags for text wherever it might be and fetch the important data.
def extract_location_from_result(soup):
locations = []
spans = soup.findAll(‘span’, attrs={‘class’: ‘location’})
for span in spans:
locations.append(span.text)
return(locations)extract_location_from_result(soup)
Salary
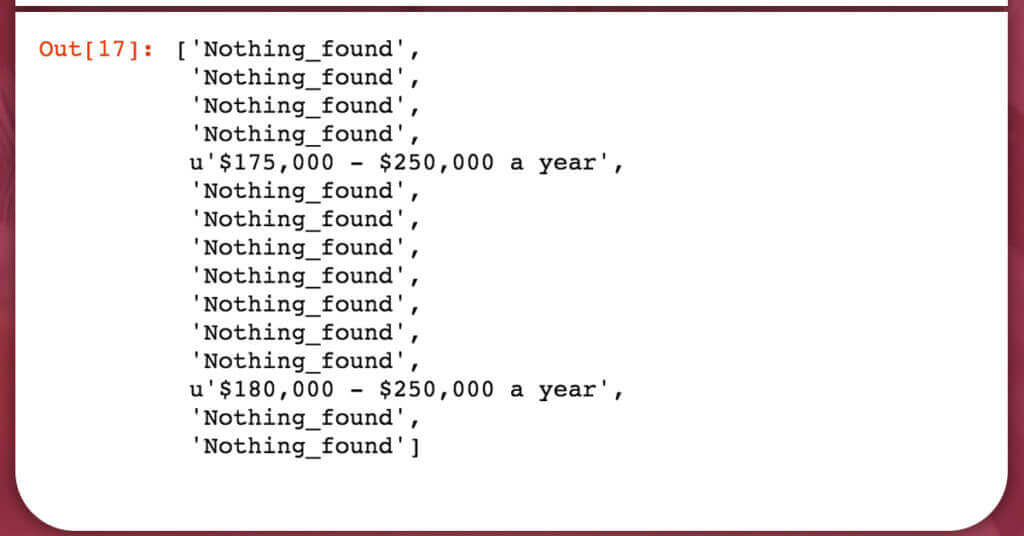
Salary is the most complicated information to scrape from job postings. Many postings do not consist of any salary information. Among those who scrape the salary information, can be in one or two different situations. Hence, we need to write a script that can take multiple places for information, and need to develop a placeholder name “Nothing found” value for those that do not contain salary information.
Some salaries come under <nobr> tags, while other comes under <div> tags, “class”: “sjcl” and needs to be separated by <div> tags with no attributes.
def extract_salary_from_result(soup):
salaries = []
for div in soup.find_all(name=”div”, attrs={“class”:”row”}):
try:
salaries.append(div.find(‘nobr’).text)
except:
try:
div_two = div.find(name=”div”, attrs={“class”:”sjcl”})
div_three = div_two.find(“div”)
salaries.append(div_three.text.strip())
except:
salaries.append(“Nothing_found”)
return(salaries)extract_salary_from_result(soup)

Job Summary
Last but not least, the job descriptions. Unfortunately, all the job summaries are not contained in the HTML from an Indeed website; nevertheless, we can gather some information about each job from the information provided. Selenium is a set of tools that may be used by a web scraper to browse through various links on a website and extract data from the full job advertisements.
Under the <span> tags, you’ll find summaries. The location text may be nested in “itemprop”: “address Locality” tags or within “class”: “location” tags. A simple for loop, on the other hand, can go through all span tags for the text and extract the information needed.
def extract_summary_from_result(soup):
summaries = []
spans = soup.findAll(‘span’, attrs={‘class’: ‘summary’})
for span in spans:
summaries.append(span.text.strip())
return(summaries)extract_summary_from_result(soup)
Merging All the Data
We have got various information regarding a scraper. Now, we just need to collect them all into the final scraper that withdraws the necessary information for every job post, keep it separate from all other job posts, and merge all the job information into a single data frame at a single time.
We can extract the initial conditions by mentioning few pieces of information.
- We can specify results that we scrape from every city of interest.
- We can create a list of all the cities for which we extract job postings.
- To save the scraped data for each posting, we can build an empty dataset. We can name our columns, where we expect each piece of information to be located in advance.
max_results_per_city = 100city_set = [‘New+York’,’Chicago’,’San+Francisco’, ‘Austin’, ‘Seattle’, ‘Los+Angeles’, ‘Philadelphia’, ‘Atlanta’, ‘Dallas’, ‘Pittsburgh’, ‘Portland’, ‘Phoenix’, ‘Denver’, ‘Houston’, ‘Miami’, ‘Washington+DC’, ‘Boulder’]columns = [“city”, “job_title”, ”company_name”, ”location”, ”summary”, ”salary”]sample_df = pd.DataFrame(columns = columns)
It goes without saying that the longer the scraping process takes, the more results you seek and the more cities you look at. This isn’t a big deal if you start your scraper before going out or going to bed, but it’s something to think about.
The actual scraper is put together using the patterns we noticed in the URL structure above. We can use this knowledge to design a loop that visits every page in a precise order to retrieve data because we know how the URLs will be patterned for each page.
#scraping code:for city in city_set:
for start in range(0, max_results_per_city, 10):
page = requests.get(‘http://www.indeed.com/jobs?q=data+scientist+%2420%2C000&l=' + str(city) + ‘&start=’ + str(start))
time.sleep(1) #ensuring at least 1 second between page grabs
soup = BeautifulSoup(page.text, “lxml”, from_encoding=”utf-8")
for div in soup.find_all(name=”div”, attrs={“class”:”row”}):
#specifying row num for index of job posting in dataframe
num = (len(sample_df) + 1)
#creating an empty list to hold the data for each posting
job_post = []
#append city name
job_post.append(city)
#grabbing job title
for a in div.find_all(name=”a”, attrs={“data-tn-element”:”jobTitle”}):
job_post.append(a[“title”])
#grabbing company name
company = div.find_all(name=”span”, attrs={“class”:”company”})
if len(company) > 0:
for b in company:
job_post.append(b.text.strip())
else:
sec_try = div.find_all(name=”span”, attrs={“class”:”result-link-source”})
for span in sec_try:
job_post.append(span.text)
#grabbing location name
c = div.findAll(‘span’, attrs={‘class’: ‘location’})
for span in c:
job_post.append(span.text)
#grabbing summary text
d = div.findAll(‘span’, attrs={‘class’: ‘summary’})
for span in d:
job_post.append(span.text.strip())
#grabbing salary
try:
job_post.append(div.find(‘nobr’).text)
except:
try:
div_two = div.find(name=”div”, attrs={“class”:”sjcl”})
div_three = div_two.find(“div”)
job_post.append(div_three.text.strip())
except:
job_post.append(“Nothing_found”)
#appending list of job post info to dataframe at index num
sample_df.loc[num] = job_post
#saving sample_df as a local csv file — define your own local path to save contents
sample_df.to_csv(“[filepath].csv”, encoding=’utf-8')
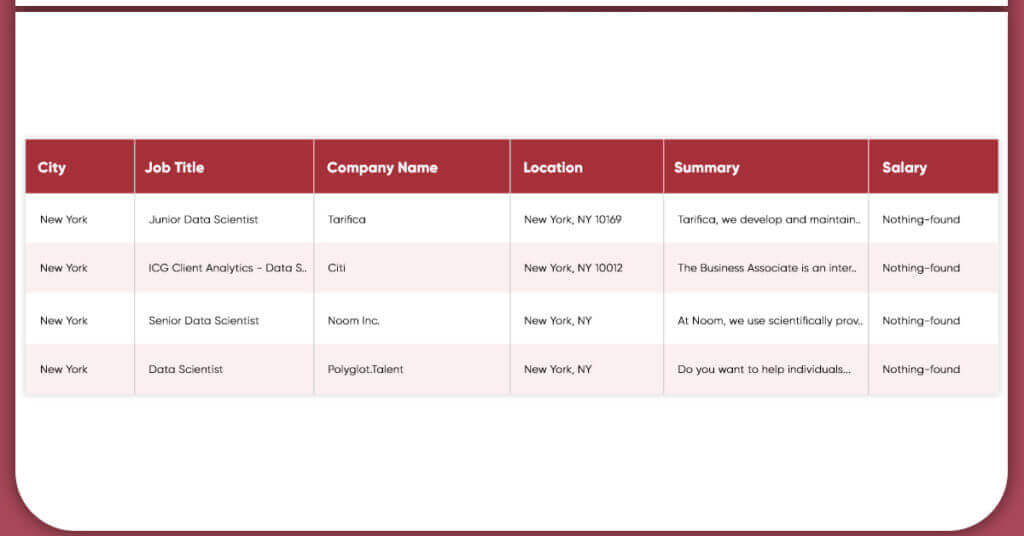
You will get own data frame for the scraped job postings after a short time.
Look how would the output be:
Contact us to request a quote!!!




